Survey about stereo matching
Basic Networks/Algorithms
U-Net: Convolutional Networks for Biomedical Image Segmentation
Info
Date
2015/05
Conference/Publication
Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015
Authors
Olaf Ronneberger, Philipp Fischer, and Thomas Brox Computer Science Department and BIOSS Centre for Biological Signalling Studies, University of Freiburg, Germany
Contributions
基于 U-Net 的改进工作:2021 Review: U-Net Family , U-Net 家族新的一些进展
skip connection的原理是什么?为什么U-net中要用到skip connection? - 知乎
- U形对称的网络结构
- skip connection(copy and crop)
浅层的网络关注纹理特征,深层的网络关注语义、本质的那种特征,所以深层浅层特征都是有各自的意义。
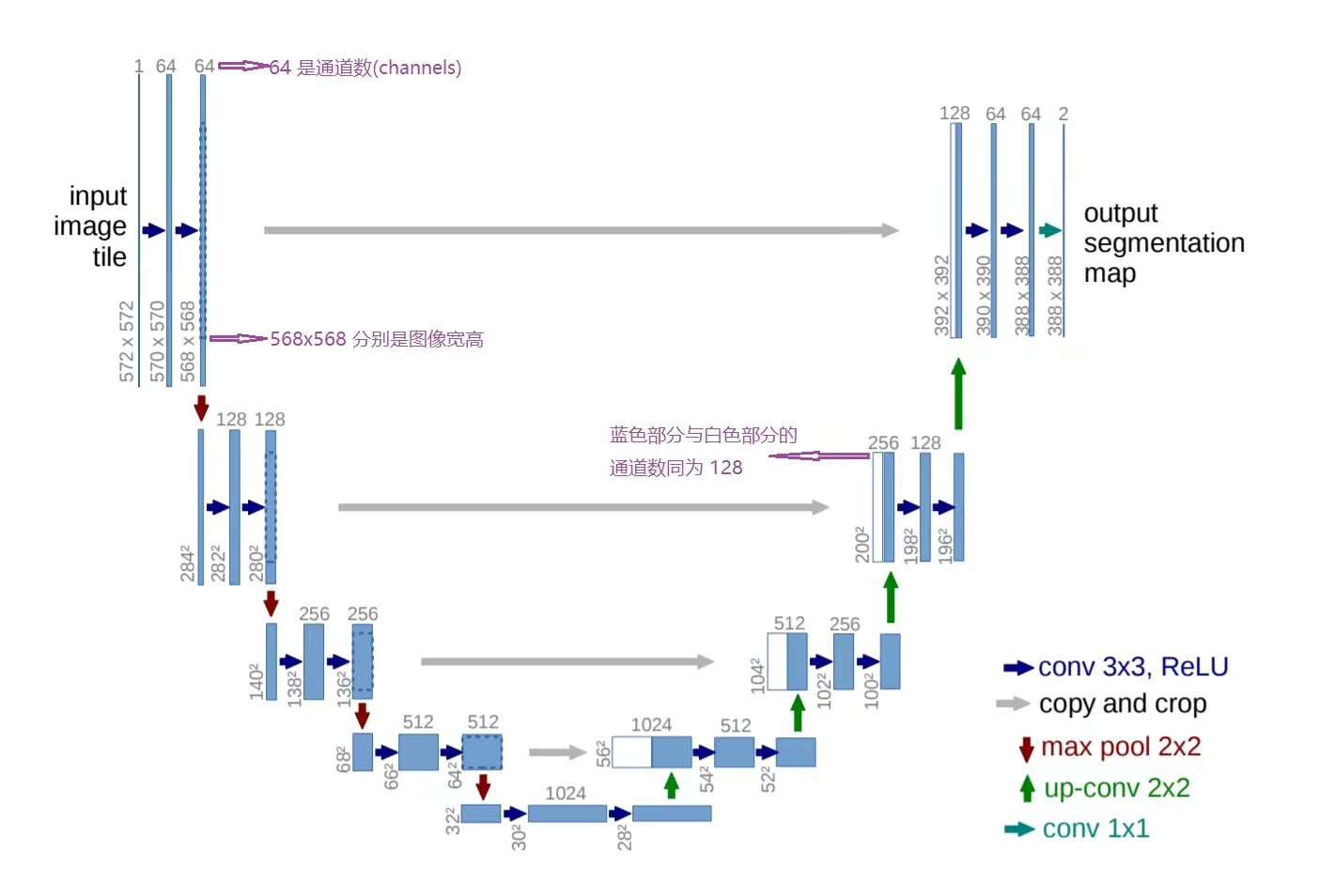 如图所示
如图所示
- 蓝色箭头:使用3x3的卷积核,没有padding(扩张图像边缘), 步长stride为1,所以每次卷积会让图像size减小2
- 红色箭头:2x2 maxpooling
- 灰色箭头:将Relu之后特征图skip过去
- channel数量:卷积核数量从64到128到256到512到1024递增,通道数量也相应递增
U-Net 使用了多个卷积核来增加通道的数量。在 U-Net 的收缩路径中,每经过一次下采样,卷积核的数量就翻倍,从 64 到 128,再到 256,直到 1024。这样做的目的是为了提取更多的特征,并且减少计算量。在 U-Net 的扩张路径中,每经过一次上采样,卷积核的数量就减半,从 1024 到 512,再到 256,直到 64。这样做的目的是为了恢复图像的分辨率,并且结合跳跃连接的特征。
U-Net 的跳跃连接是一种将编码器和解码器中对应位置的特征图在通道维度上拼接的方法,它可以保留更多的空间信息和细节信息,从而提高分割的精度和质量。
feature map 的维度没有变化,但每个维度都包含了更多特征,对于普通的分类任务这种不需要从 feature map 复原到原始分辨率的任务来说,这是一个高效的选择;而拼接则保留了更多的维度/位置 信息,这使得后面的 layer 可以在浅层特征与深层特征自由选择,这对语义分割任务来说更有优势。
U-Net 中的 encoder 和 decoder 思想是将图像分割任务分为两部分:特征提取和特征融合。
encoder 负责从输入图像中提取特征。encoder 通常使用卷积和池化操作来逐渐降低图像的分辨率,同时增加图像的通道数。通过这种方式,encoder 可以从图像中提取出与图像语义相关的特征。
decoder 负责将 encoder 提取的特征进行融合,生成输出图像。decoder 通常使用反卷积和上采样操作来逐渐提高图像的分辨率,同时减少图像的通道数。通过这种方式,decoder 可以将 encoder 提取的特征进行融合,生成与输入图像语义一致的输出图像。
这种思想之所以行得通,是因为它可以有效地利用图像的局部和全局信息。encoder 可以提取图像的局部信息,decoder 可以利用 encoder 提取的局部信息来生成输出图像。
具体来说,encoder 可以提取图像的边缘、纹理等局部信息。这些局部信息对于图像分割任务非常重要。decoder 可以利用 encoder 提取的局部信息来定位图像中的目标区域。
此外,encoder 和 decoder 的设计可以有效地防止模型过拟合。encoder 可以将图像的分辨率降低,从而减少模型的参数数量。decoder 可以使用上采样操作来提高图像的分辨率,从而避免模型丢失细节信息。
总而言之,U-Net 中的 encoder 和 decoder 思想是一种有效的图像分割方法。它可以有效地利用图像的局部和全局信息,防止模型过拟合。
encoder 和 decoder 的思想之所以能够广泛应用,是因为它可以有效地将一个任务分为两部分:特征提取和特征融合。这种思想可以简化任务的复杂度,提高模型的性能。
以下是一些具体的案例:
- 图像分割:U-Net 是一种使用 encoder-decoder 结构的图像分割模型。它已经被证明在各种图像分割任务中具有良好的性能。
- 机器翻译:Transformer 是一种使用 encoder-decoder 结构的神经网络模型。它在机器翻译任务中取得了 state-of-the-art 的效果。
- 语音识别:DeepSpeech 是一种使用 encoder-decoder 结构的语音识别模型。它在语音识别任务中取得了良好的效果。
ResNet: Deep Residual Learning for Image Recognition
Info
形而上的理解:
每一层的网络无需对上一层或下一层负责,只需要对自己的残差负责即可。
Contributions
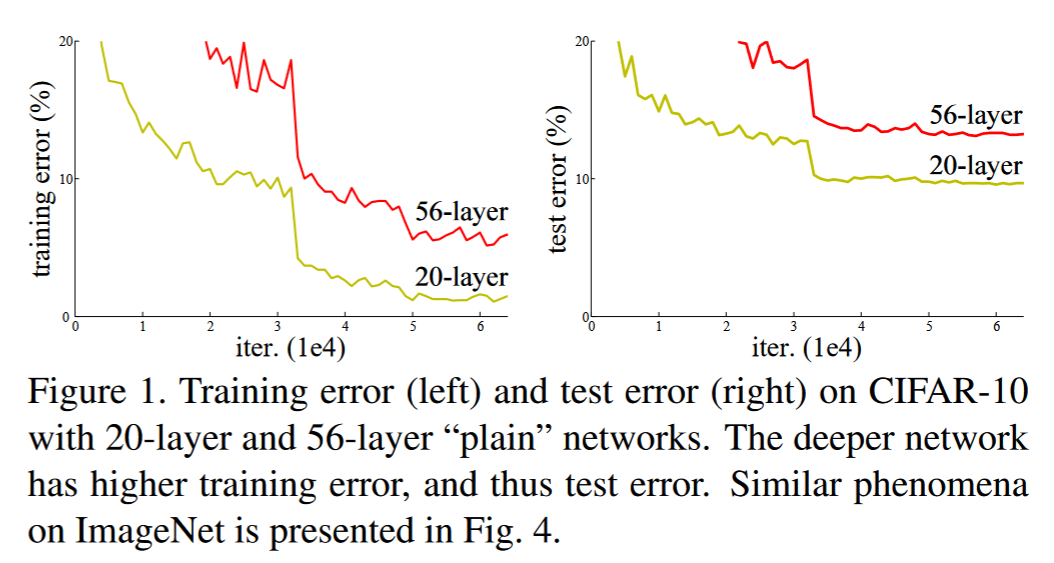
随着网络层数增加会出现退化现象,层数多一定值,精度突然下降。
ResNet团队把退化现象归因为深层神经网络难以实现“恒等变换(y=x)”
ResNet详解——通俗易懂版 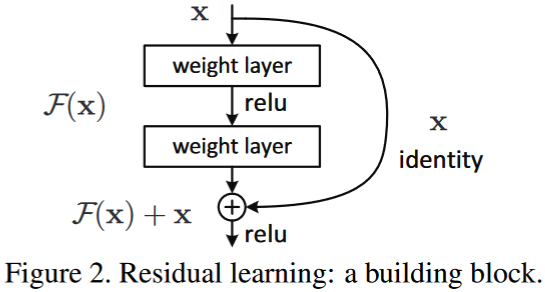 要求解的映射为:H(x) 现在将这个问题转换为求解网络的残差映射函数,也就是F(x),其中F(x) = H(x)-x。
要求解的映射为:H(x) 现在将这个问题转换为求解网络的残差映射函数,也就是F(x),其中F(x) = H(x)-x。
- H(x)就是观测值
- x是估计值(也就是上一层ResNet输出的特征映射)
- 我们一般称x为identity Function,它是一个跳跃连接
- 称F(x)为ResNet Function
如果是采用一般的卷积神经网络的化,原先要求解的是H(x) = F(x)?那么,现在假设,在网络达到某一个深度的时候,咱们的网络已经达到最优状态了,也就是说,此时的错误率是最低的时候,再往下加深网络的化就会出现退化问题(错误率上升的问题)。咱们现在要更新下一层网络的权值就会变得很麻烦,权值得是一个让下一层网络同样也是最优状态才行。对吧? 但是采用残差网络就能很好的解决这个问题。还是假设当前网络的深度能够使得错误率最低,如果继续增加咱们的ResNet,为了保证下一层的网络状态仍然是最优状态,咱们只需要把令F(x)=0就好啦!因为x是当前输出的最优解,为了让它成为下一层的最优解也就是希望咱们的输出H(x)=x的话,是不是只要让F(x)=0就行了? 当然上面提到的只是理想情况,咱们在真实测试的时候x肯定是很难达到最优的,但是总会有那么一个时刻它能够无限接近最优解。采用ResNet的话,也只用小小的更新F(x)部分的权重值就行啦!不用像一般的卷积层一样大动干戈!
当UNet遇见ResNet会发生什么?https://zhuanlan.zhihu.com/p/128138930
\[\frac{dloss}{dx}=\frac{dloss}{dy}\times\frac{dy}{dx}=\frac{dloss}{dy}*(1+\frac{dF(x,W)}{dx})\]首先,浅层网络都是希望学习到一个恒等映射函数 $H(x)=x$, 其中=指的是用 $H(x)$ 这个特征/函数来代表原始的 $x$ 的信息,但随着网络的加深这个恒等映射变得越来越难以拟合。即是用 BN 这种技巧存在,在深度足够大的时候网络也会难以学习这个恒等映射关系。因此 ResNet 提出将网络设计为 $H(x)=F(x)+x$, 然后就可以转换为学习一个残差函数 $F(x)=H(x)-x$, 只要残差为 0,就构成了一个恒等映射 $H(x)=x$, 并且相对于拟合恒等映射关系,拟合残差更容易。残差结构具体如Figure2所示,identity mapping 表示的就是恒等映射,即是将浅层网络的特征复制来和残差构成新的特征。其中恒等映射后面也被叫作跳跃连接(skip connrection)或者短路连接(shortcut connection), 这一说法一直保持到今天。同时我们可以看到一种极端的情况是残差映射为0,残差模块就只剩下$x$,相当于什么也不做,这至少不会带来精度损失,这个结构还是比较精巧的。 为什么残差结构是有效的呢? 这是因为引入残差之后的特征映射对输出的变化更加敏感,也即是说梯度更加,更容易训练。 从图2可以推导一下残差结构的梯度计算公式,假设从浅层到深层的学习 特征 $y=x+F(x,W)$, 其中 $F(x,W)$ 就是带权重的卷积之后的结果,我们可以反向求出损失对 x 的梯度$dloss/dx$:
其中$\frac{dloss}{dy}$代表损失函数在最高层的梯度,小括号中的 1 表示残差连接可以无损的传播梯度,而另外一项残差的梯度则需要经过带有可学习参数的卷积层。另外残差梯度不会巧合到全部为 -1, 而且就算它非常小也还有 1 这一项存在,因此梯度会稳定的回传,不用担心梯度消失。同时因为残差一般会比较小,残差学习需要学习的内容少,学习难度也变小,学习就更容易。
skip connection的原理是什么?为什么U-net中要用到skip connection? - SuperMHP的回答 - 知乎
1.从Resnet最早引入 skip-connection 的角度看,这种跳跃连接可以有效的减少梯度消失和网络退化问题,使训练更容易。直观上理解可以认为BP的时候,深层的梯度可以更容易的传回浅层,因为这种结构的存在,对神经网络层数的设定可以更随意一些。不带 skip connection 的网络层数深了非凸性暴增。2.从微分方程角度看,skip-connection 的加入会使得具体一层可以替代为差分预测机,这种理解对于resnet已经被一定数量的工作阐明
Result
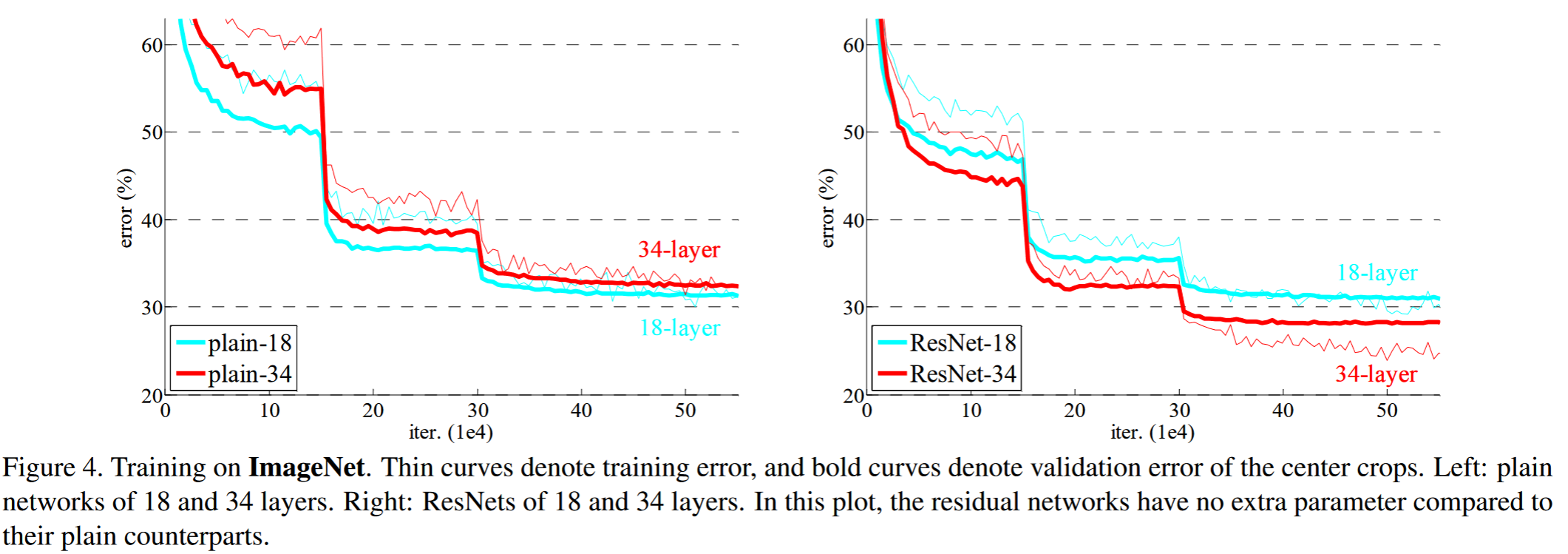
Normal Camera
BGNet:Bilateral Grid Learning for Stereo Matching Networks
Info
Date
2021/06
Conference/Publication
2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Author
Bin Xu1, Yuhua Xu1,2,∗, Xiaoli Yang1, Wei Jia2, Yulan Guo3 1Orbbec, 2Hefei University of Technology, 3Sun Yat-sen University
Contributions
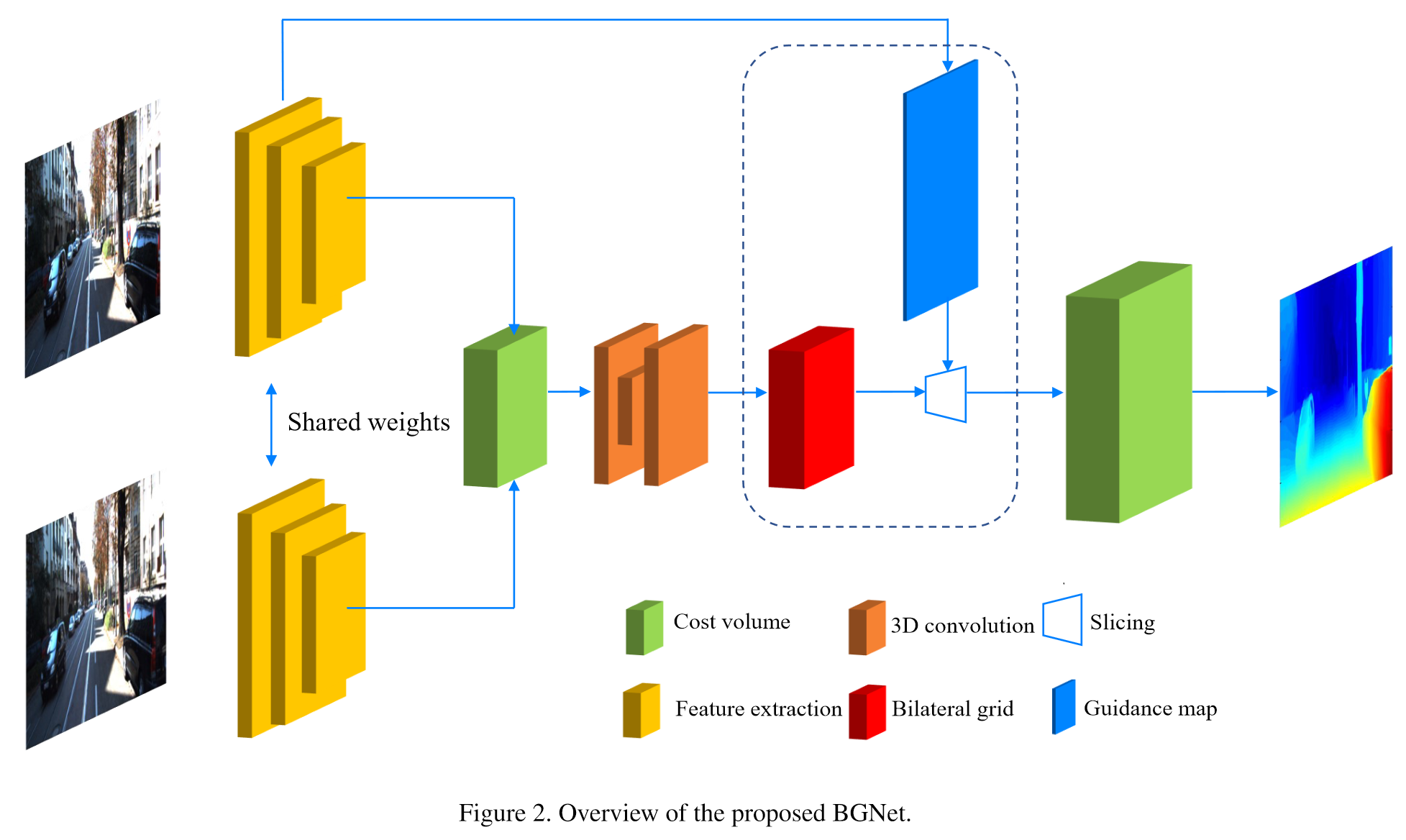 解决了实时处理速度与精度的矛盾,构造低分辨率4D cost volume, 设计基于双边网格的无参数切片层,从低分辨率 cost volume 中获得边缘保持的高分辨率 cost volume,加速计算。
解决了实时处理速度与精度的矛盾,构造低分辨率4D cost volume, 设计基于双边网格的无参数切片层,从低分辨率 cost volume 中获得边缘保持的高分辨率 cost volume,加速计算。
Result
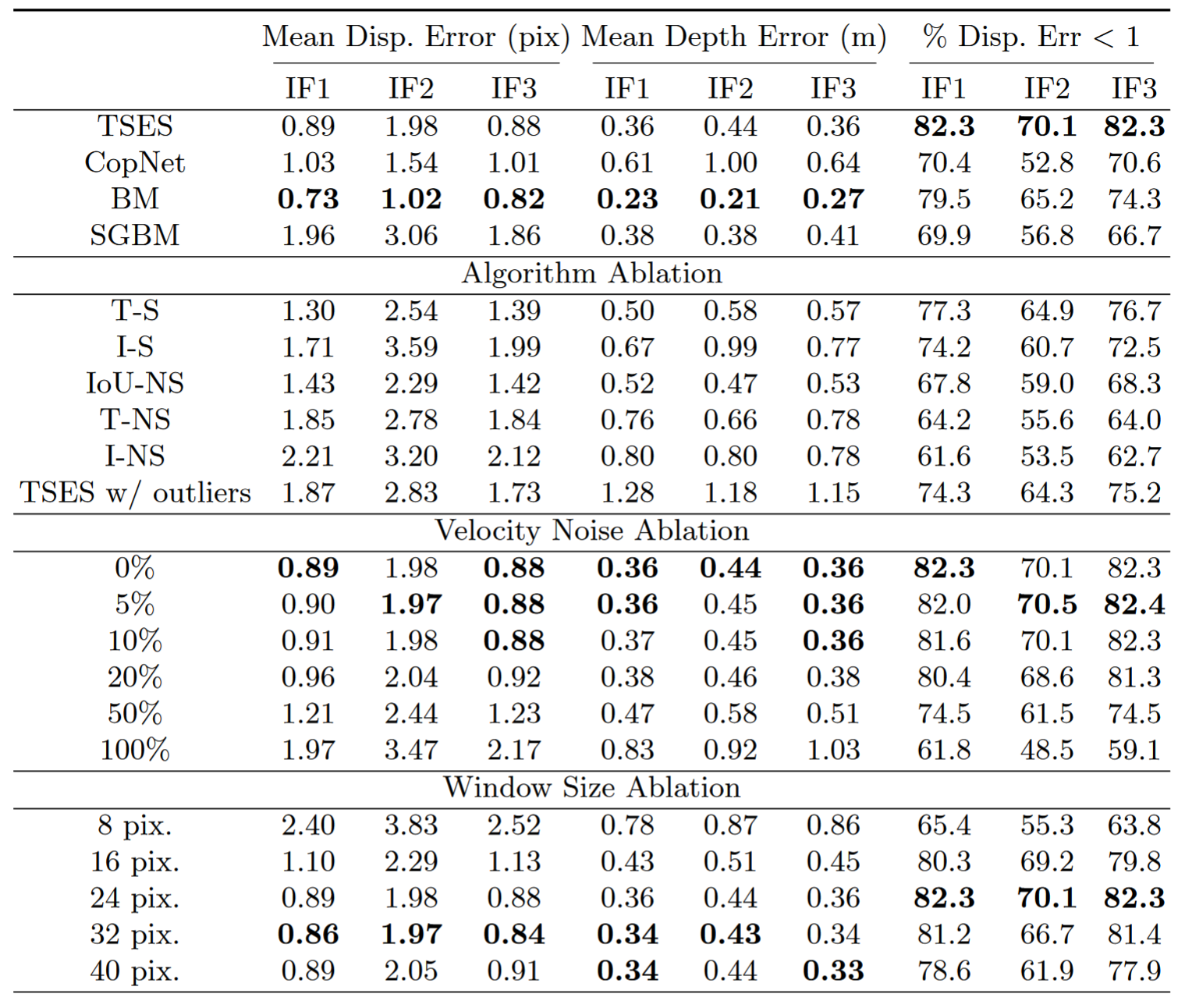
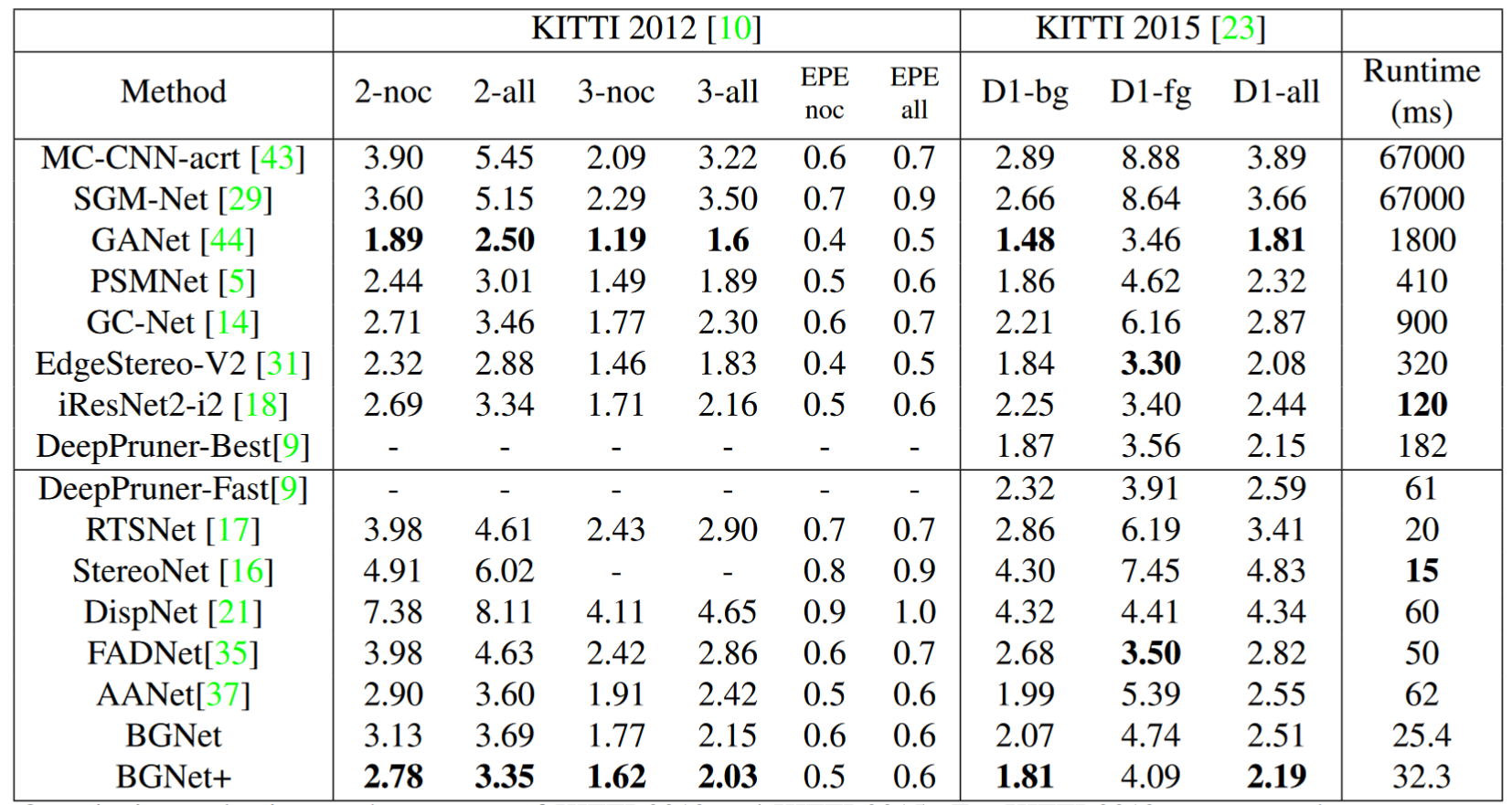
精度:在 KITTI2015 上 2-noc 达到1.81
速度:耗时32.3ms, 31FPS
Comments
bilateral grid 实现了较快的速度,使用卷积构建 cost volume 还是消耗了较多时间(20ms with RTX3080) 使用PSMNet的 finetune 代码  —
—
ACVNet:Attention Concatenation Volume for Accurate and Efficient Stereo Matching
Info
Date
2022/06
Conference/Publication
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Author
Gangwei Xu1, Junda Cheng1, Peng Guo1 , Xin Yang1,2 1School of EIC, Huazhong University of Science & Technology 2Wuhan National Laboratory for Optoelectronics
Contributions
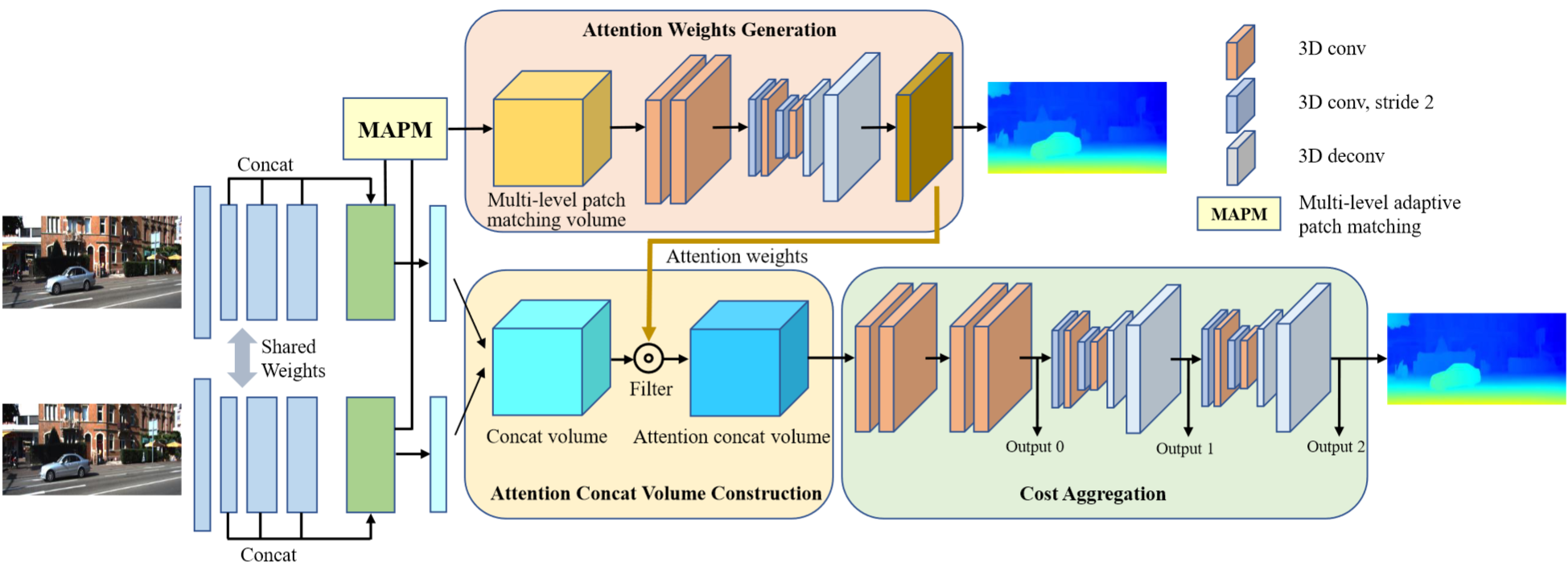 过去的工作构建 cost volume 消耗大量计算资源与时间,文章旨在探索一种更高效、更有效的cost volume形式,既能显著减轻构建 cost aggregation 的负担,又能达到最先进的精度。 提出了一种基于关联线索生成注意理权值(generates attention weights from correlation clues)的 cost volume 构建方法,以抑制冗余信息,增强 concatenation volume 中的匹配相关信息。 为了产生可靠的注意力权重,文章提出了多级自适应补丁匹配(MAPM, multi-level adaptive patch matching),以对稀疏和无纹理区域的检测。所提出的代价体积被称为注意力拼接体积(attention concatation volume, ACV), ACV可以无缝嵌入到大多数立体匹配网络中,所得到的网络可以使用更轻量的聚合网络,同时获得更高的精度,例如仅使用聚合网络的1/25参数就可以获得更高的精度。
过去的工作构建 cost volume 消耗大量计算资源与时间,文章旨在探索一种更高效、更有效的cost volume形式,既能显著减轻构建 cost aggregation 的负担,又能达到最先进的精度。 提出了一种基于关联线索生成注意理权值(generates attention weights from correlation clues)的 cost volume 构建方法,以抑制冗余信息,增强 concatenation volume 中的匹配相关信息。 为了产生可靠的注意力权重,文章提出了多级自适应补丁匹配(MAPM, multi-level adaptive patch matching),以对稀疏和无纹理区域的检测。所提出的代价体积被称为注意力拼接体积(attention concatation volume, ACV), ACV可以无缝嵌入到大多数立体匹配网络中,所得到的网络可以使用更轻量的聚合网络,同时获得更高的精度,例如仅使用聚合网络的1/25参数就可以获得更高的精度。
Result
精度:ACV 将 PSMNet 和 GwcNet 的准确率分别提高了 42% 和 39%。ACVNet 在 KITTI 2012 和 KITTI 2015 上排名第2,在 Scene Flow 上排名第2,在ETH3D上排名第3. 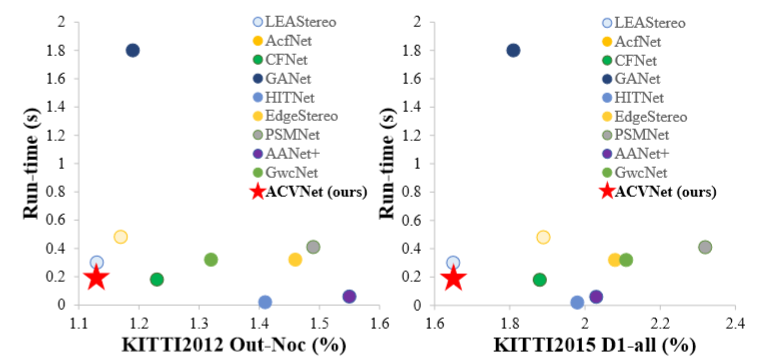 速度:0.2s
速度:0.2s 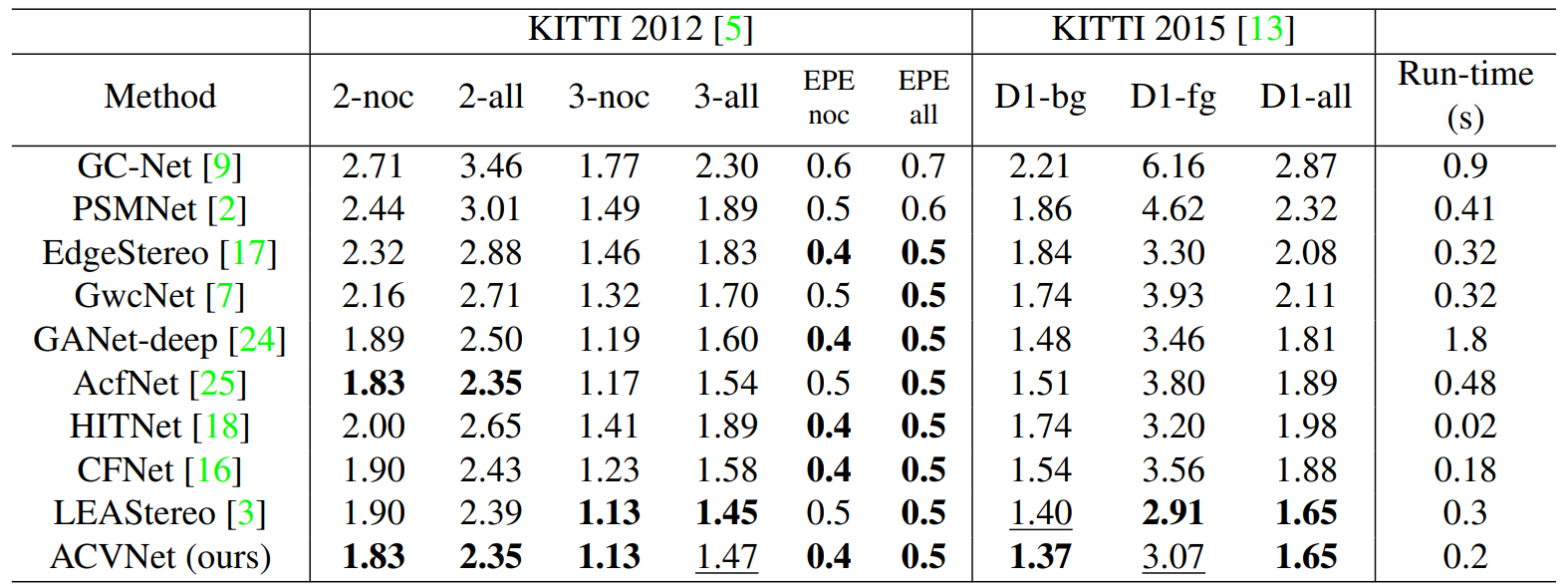
Comments
引入了注意力机制 attention weights from correlation clues
Fast-ACVNet:Accurate and Efficient Stereo Matching via Attention Concatenation Volume
Info
Date
2023/11 Preprint
Conference/Publication
IEEE Transactions on Pattern Analysis and Machine Intelligence
Author
Gangwei Xu, Yun Wang, Junda Cheng, Jinhui Tang, Xin Yang School of EIC, Huazhong University of Science & Technology
Contributions
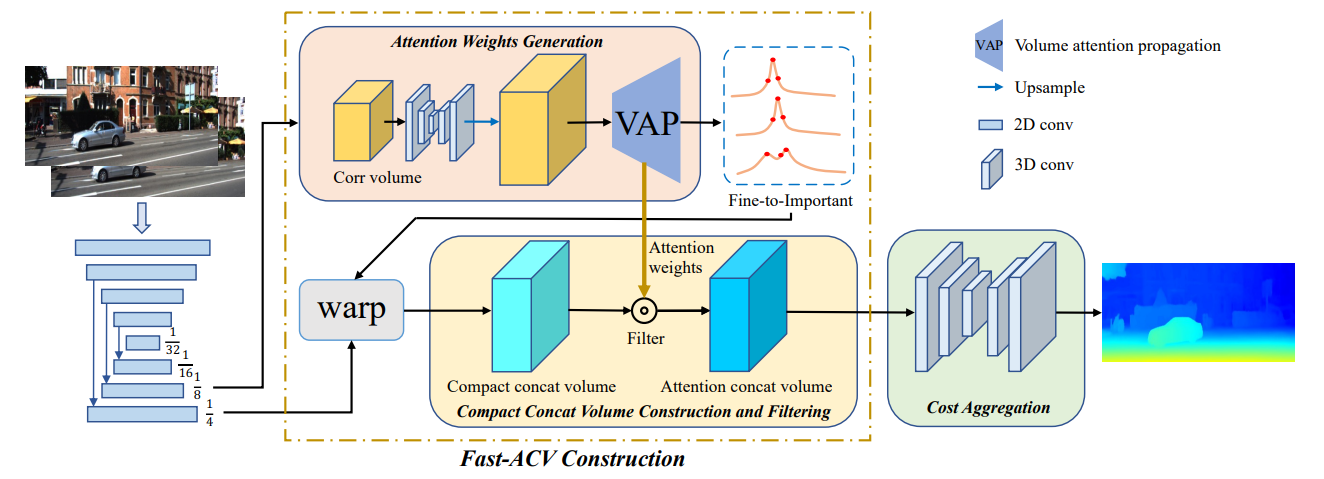 文章进一步设计了一个快速版本的ACV,以实现实时性能,命名为Fast -ACVNet,它从低分辨率的相关线索中产生高似然差异假设和相应的注意权重,从而显着降低计算和内存成本,同时保持准确。 Fast-ACV的核心思想包括批量注意传播(VAP)和精细到重要(F2I)策略。 VAP可以自动从插值的相关体积中选择准确的相关值,并将这些准确的相关值传播到具有模糊相关线索的周围像素,F2I可以生成一组具有高似然的差异假设和相应的注意权值,从而显著抑制拼接体积中不可能存在的差异,从而减少时间和内存成本。
文章进一步设计了一个快速版本的ACV,以实现实时性能,命名为Fast -ACVNet,它从低分辨率的相关线索中产生高似然差异假设和相应的注意权重,从而显着降低计算和内存成本,同时保持准确。 Fast-ACV的核心思想包括批量注意传播(VAP)和精细到重要(F2I)策略。 VAP可以自动从插值的相关体积中选择准确的相关值,并将这些准确的相关值传播到具有模糊相关线索的周围像素,F2I可以生成一组具有高似然的差异假设和相应的注意权值,从而显著抑制拼接体积中不可能存在的差异,从而减少时间和内存成本。
Result
精度:SOTA on KITTI 速度:由ACVNet的0.2s提升到45ms 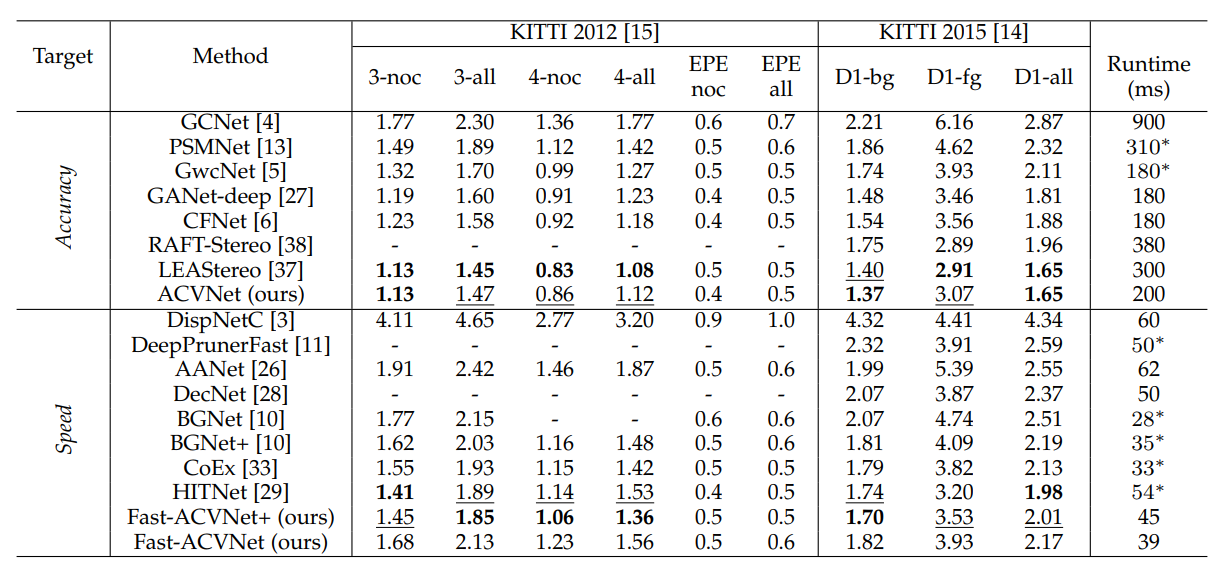
Comments
提出VAP和F2I策略,显著降低计算和内存成本,同时保持准确。
HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching
Info
Date
2021/06
Conference/Publication
2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Author
Vladimir Tankovich Christian H ̈ ane Yinda Zhang Adarsh Kowdle Sean Fanello Sofien Bouaziz Google
Contributions
解决了构建cost volume 的计算和内存成本高的问题。 与最近许多在全成本体积上运行并依赖3D卷积的神经网络方法相反,我们的方法不明确地构建体积,而是依赖于快速的多分辨率初始化步骤、可微分的2D几何传播和扭曲机制来推断视差假设。为了达到较高的精度,网络不仅从几何上推断差异,而且还推断斜面假设,从而更准确地执行几何翘曲和上采样操作。其计算量仅为最先进方法的一小部分。
Result
精度:ETH3D排名第3,在Middlebury-v3上所有端到端学习排名第1,在流行的KITTI 2012和2015基准中排名第1 速度:0.02s, 50FPS 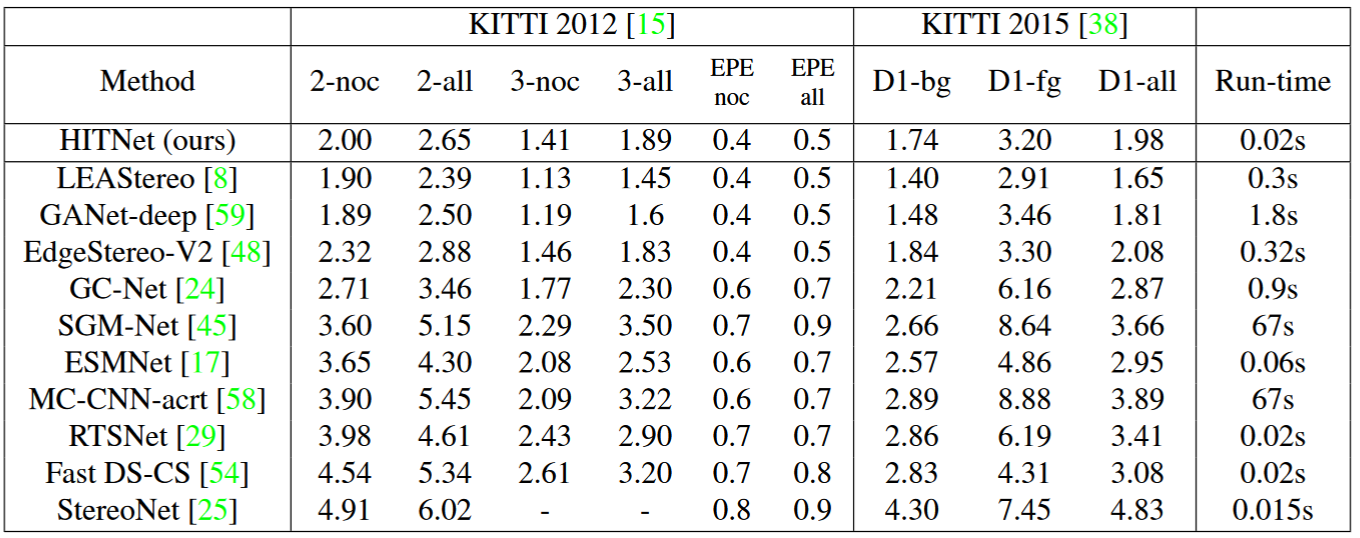
Comments
基于传统算法的改进,跳过了构建 cost volume 的步骤,显著降低计算和内存成本,提高速度。 但是官方目前开源的 tensorflow model 运行速度是论文中的三倍。 https://github.com/google-research/google-research/tree/master/hitnet
The released models are using default tensoflow ops which causes them to be 3X slower than the same models that use custom CUDA ops. The custom CUDA ops and a version of the models that use them may be released later.
AANet: Adaptive Aggregation Network for Efficient Stereo Matching
Info
Date
2020/06
Conference/Publication
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Author
Haofei Xu Juyong Zhang University of Science and Technology of China
Contributions
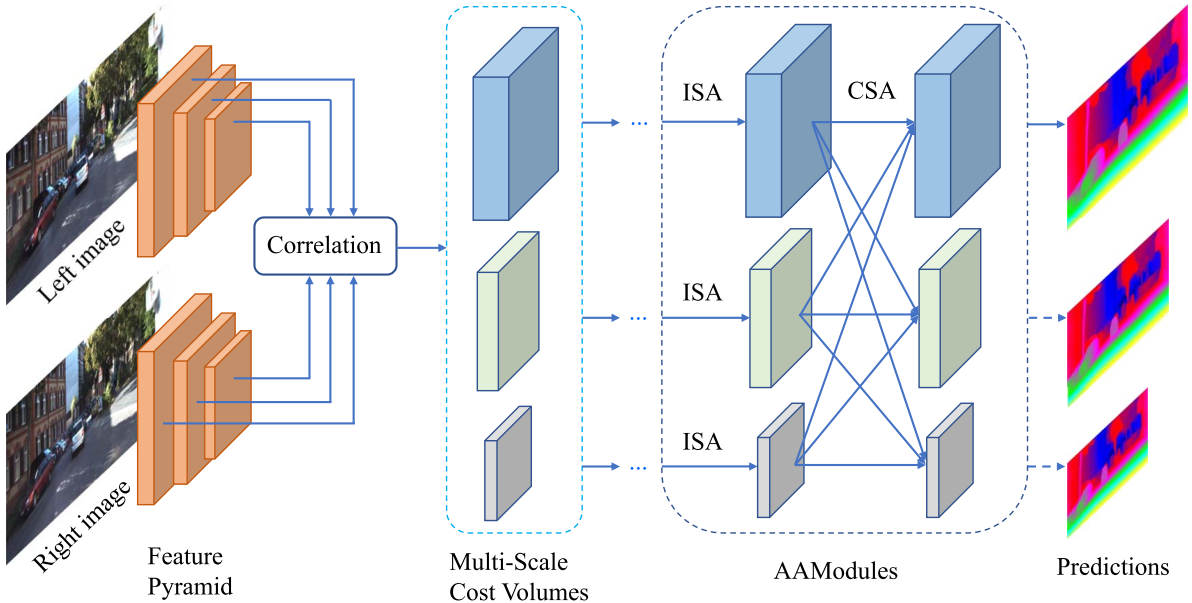 尽管基于学习的立体匹配算法取得了显著进展,但仍有一个关键挑战尚未解决。目前最先进的立体模型大多基于昂贵的3D卷积,立方计算的复杂性和高内存消耗使其在实际应用中部署相当昂贵。 文章创新点是完全取代常用的3D卷积来实现快速的推理速度,同时主要保持相当的精度。为此,文章首先提出了一种基于稀疏点的尺度内成本聚合方法,以缓解视差不连续处众所周知的 edge-fattening issue。进一步,文章用神经网络层近似传统的跨尺度代价聚合算法来处理大型无纹理区域。这两个模块都是简单、轻量级和互补的,可为成本聚合提供一个有效和高效的体系结构。
尽管基于学习的立体匹配算法取得了显著进展,但仍有一个关键挑战尚未解决。目前最先进的立体模型大多基于昂贵的3D卷积,立方计算的复杂性和高内存消耗使其在实际应用中部署相当昂贵。 文章创新点是完全取代常用的3D卷积来实现快速的推理速度,同时主要保持相当的精度。为此,文章首先提出了一种基于稀疏点的尺度内成本聚合方法,以缓解视差不连续处众所周知的 edge-fattening issue。进一步,文章用神经网络层近似传统的跨尺度代价聚合算法来处理大型无纹理区域。这两个模块都是简单、轻量级和互补的,可为成本聚合提供一个有效和高效的体系结构。
Result
精度:在运行62ms时,我们还在场景流和KITTI数据集上取得了具有竞争力的结果
速度:62ms,比GC-Net快41倍,比PSMNet快4倍,比GANet快38倍 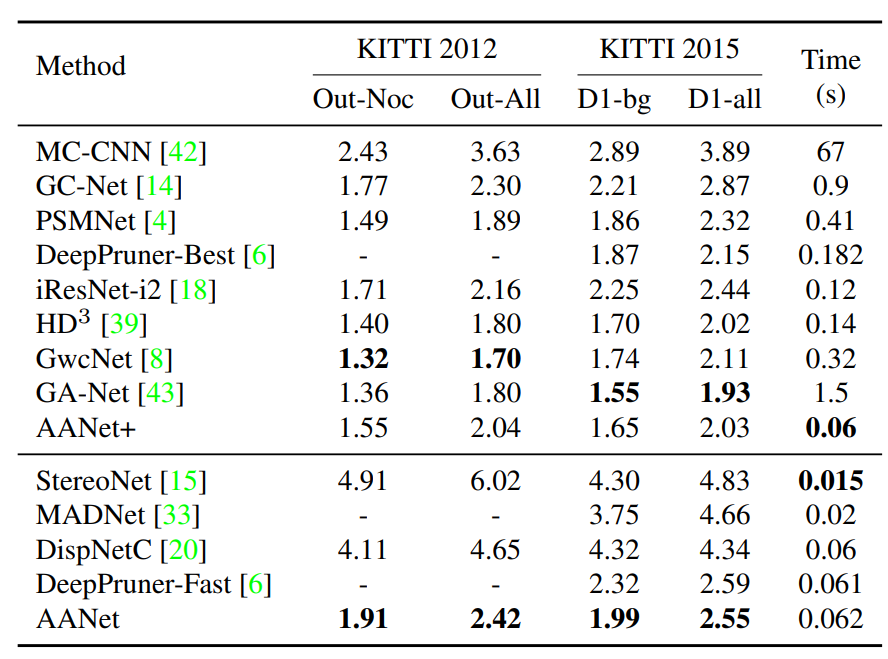
Comments
使用了稀疏卷积+跨尺度融合 use 4 NVIDIA V100 GPUs (32G) with batch size 64 for training
RealtimeStereo: Attention-Aware Feature Aggregation for Real-Time Stereo Matching on Edge Devices
Info
Date
2020
Conference/Publication
ACCV
Author
Jia-Ren Chang1,2, Pei-Chun Chang1, and Yong-Sheng Chen1 1 Department of Computer Science National Chiao Tung University
Contributions
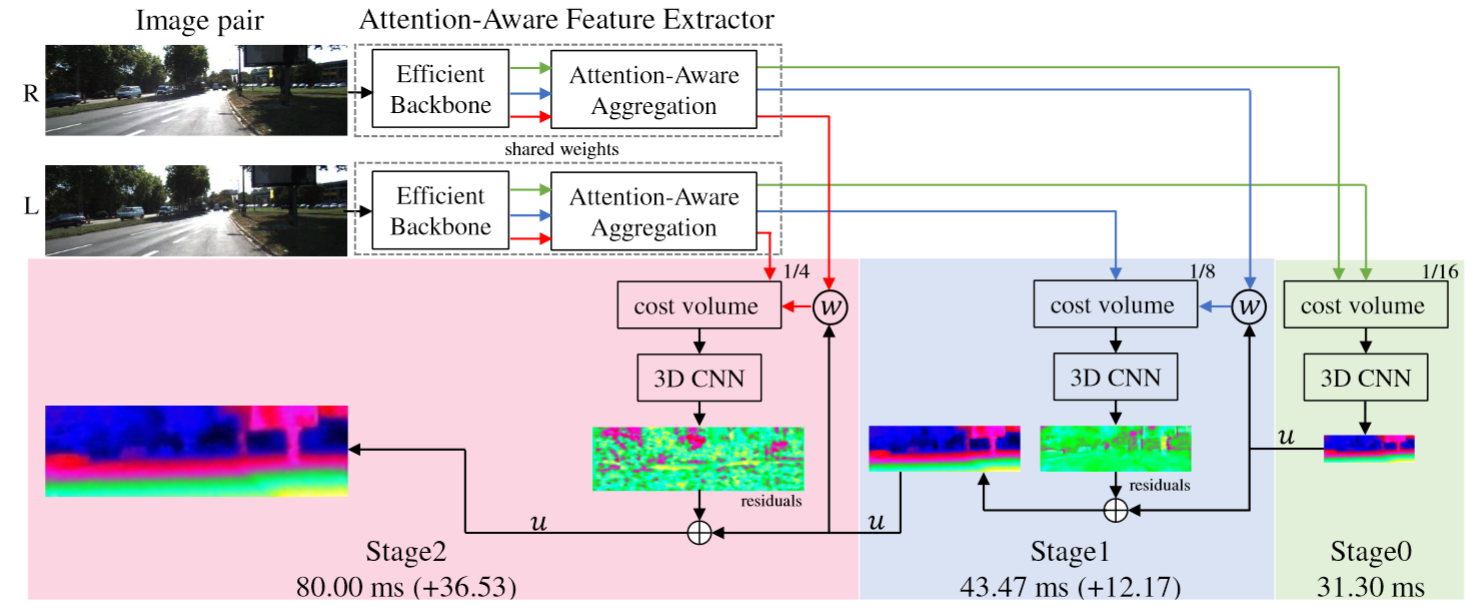 PSMNet 基于 3D 卷积,在边缘设备上运行速度较慢。最近的工作已经证明了使用卷积神经网络从一对立体图像进行深度估计的优异结果。然而,这些方法需要大量的计算资源,并且不适合边缘设备上的实时应用。在这项工作中,我们提出了一种在边缘设备上进行实时立体匹配的新方法,该方法由用于特征提取的高效主干、注意力感知特征聚合和用于多尺度视差估计的级联 3D CNN 架构组成。高效的主干网旨在生成计算能力有限的多尺度特征图。通过所提出的注意感知特征聚合模块进一步自适应地聚合多尺度特征图,以提高特征的表示能力。多尺度成本量是使用聚合特征图构建的,并使用级联 3D CNN 架构进行正则化,以估计任何设置下的视差图。网络推断低分辨率下的视差图,然后通过计算视差残差逐步细化更高分辨率下的视差图。由于信息特征的有效提取和聚合,该方法可以在实时推理中实现准确的深度估计。
PSMNet 基于 3D 卷积,在边缘设备上运行速度较慢。最近的工作已经证明了使用卷积神经网络从一对立体图像进行深度估计的优异结果。然而,这些方法需要大量的计算资源,并且不适合边缘设备上的实时应用。在这项工作中,我们提出了一种在边缘设备上进行实时立体匹配的新方法,该方法由用于特征提取的高效主干、注意力感知特征聚合和用于多尺度视差估计的级联 3D CNN 架构组成。高效的主干网旨在生成计算能力有限的多尺度特征图。通过所提出的注意感知特征聚合模块进一步自适应地聚合多尺度特征图,以提高特征的表示能力。多尺度成本量是使用聚合特征图构建的,并使用级联 3D CNN 架构进行正则化,以估计任何设置下的视差图。网络推断低分辨率下的视差图,然后通过计算视差残差逐步细化更高分辨率下的视差图。由于信息特征的有效提取和聚合,该方法可以在实时推理中实现准确的深度估计。
Result
实验结果表明,该方法在 NVIDIA Jetson TX2 模块上以 12-33 fps 处理分辨率为 1242×375 的立体图像对,并在深度估计方面实现了有竞争力的精度。 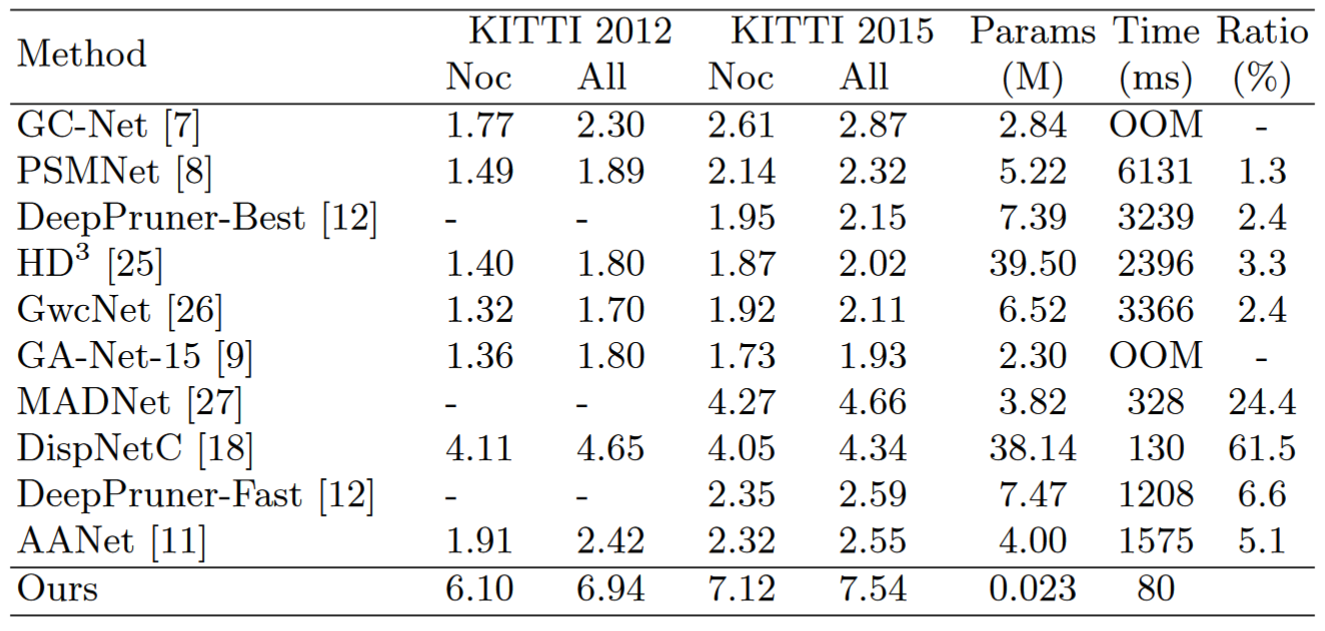
PSMNet: Pyramid Stereo Matching Network
Info
Date
2018/06
Conference/Publication
2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition
Author
Jia-Ren Chang Yong-Sheng Chen Department of Computer Science, National Chiao Tung University, Taiwan
Contributions
Disparity Estimation Using Deep Learning
Volumetric Methods
Volumetric methods leverage the concept of semi-global matching and build a 4D-feature volume, by concatenating features from each disparity shift. It has four major components:
- A feature net to extract features from the input images
- A cost-volume module to concatenate the features extracted from the left and right images
- A matching net to compute matching costs from the 4D-feature volume with 3D convolutions
- The regression module to regress disparity
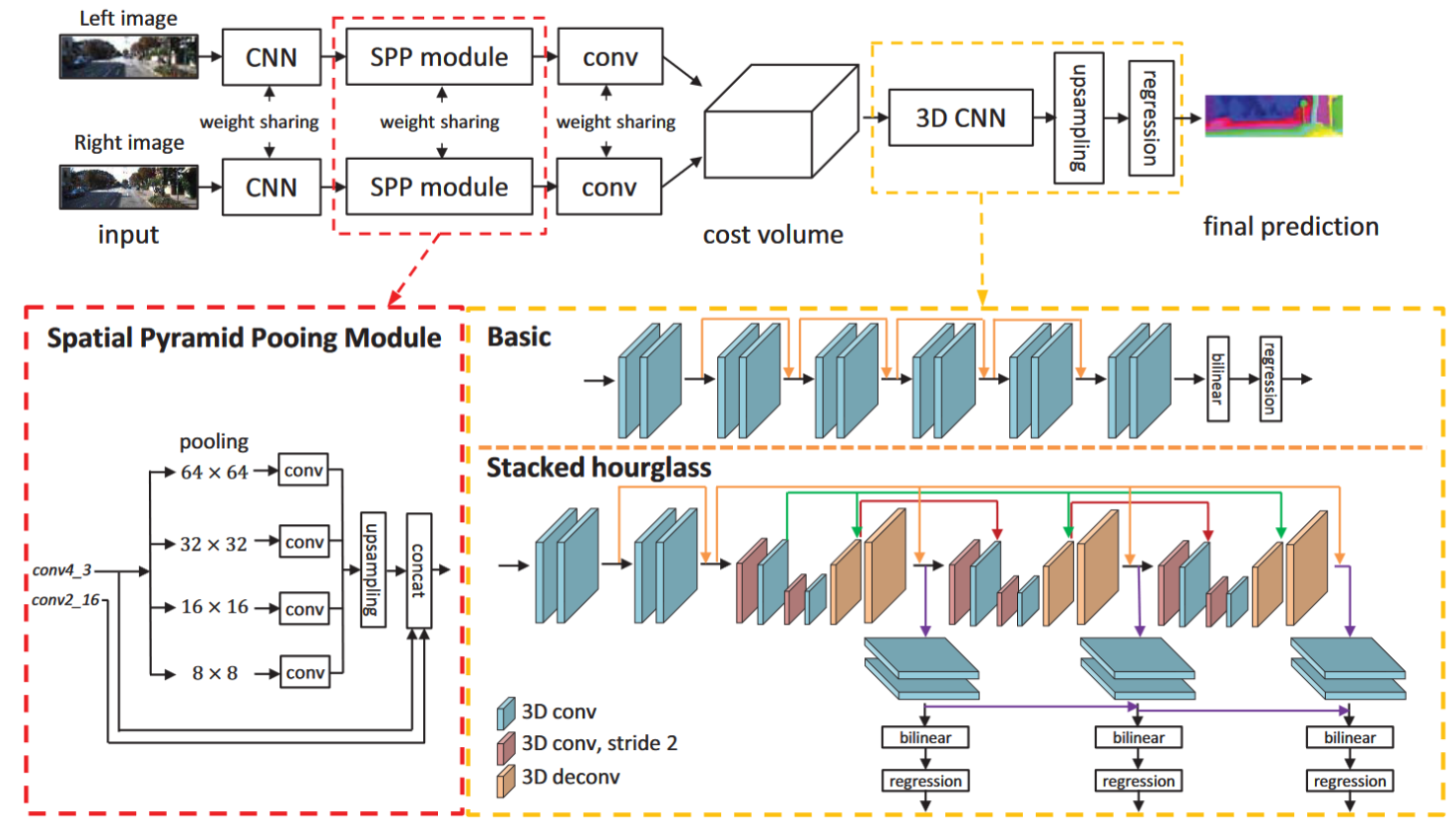 最近的工作表明,立体图像对的深度估计可以制定为监督学习任务,通过卷积神经网络(CNN)来解决。然而,当前的架构依赖于基于补丁的暹罗网络,缺乏利用上下文信息来查找不适定区域中的对应关系的方法。为了解决这个问题,我们提出了 PSMNet,一种金字塔立体匹配网络,由两个主要模块组成:空间金字塔池化和 3D CNN。空间金字塔池化模块通过聚合不同尺度和位置的上下文来形成成本量,从而利用全局上下文信息的容量。 3D CNN 学习使用堆叠的多个沙漏网络并结合中间监督来规范成本量。 立体匹配论文笔记(一):PSM-Net
最近的工作表明,立体图像对的深度估计可以制定为监督学习任务,通过卷积神经网络(CNN)来解决。然而,当前的架构依赖于基于补丁的暹罗网络,缺乏利用上下文信息来查找不适定区域中的对应关系的方法。为了解决这个问题,我们提出了 PSMNet,一种金字塔立体匹配网络,由两个主要模块组成:空间金字塔池化和 3D CNN。空间金字塔池化模块通过聚合不同尺度和位置的上下文来形成成本量,从而利用全局上下文信息的容量。 3D CNN 学习使用堆叠的多个沙漏网络并结合中间监督来规范成本量。 立体匹配论文笔记(一):PSM-Net
In PSMNet/models/basic.py:
左右视图提取特征的网络都是共享权重的。SPP模块是四个不同尺度的池化,再上采样串联起来,整合多尺度的信息。送到cost volume之前左右图的特征是(1,32,96,312)维度的,32是通道数,96*312是输入图像分辨率的1/4,1是batch size,后面的cost volume的1也是这个,就不管了。cost volume的维度是(1,64,48,96,312),64的前32个通道是左视图的,后32个通道是右视图的;48代表视差等级的维度,即视差为0-47px(设置最大视差为191px,后面会上采样)。 比如现在i=10,即cost volume的第三个维度视差为10px时,第二个维度的前32个通道取左图x轴上10以后的像素,后32个通道取右图x轴上去掉最后10像素的所有,其他地方都是0。
1
2
3
4
for i in range(self.maxdisp/4):
if i > 0 :
cost[:, :refimg_fea.size()[1], i, :,i:] = refimg_fea[:,:,:,i:]
cost[:, refimg_fea.size()[1]:, i, :,i:] = targetimg_fea[:,:,:,:-i]
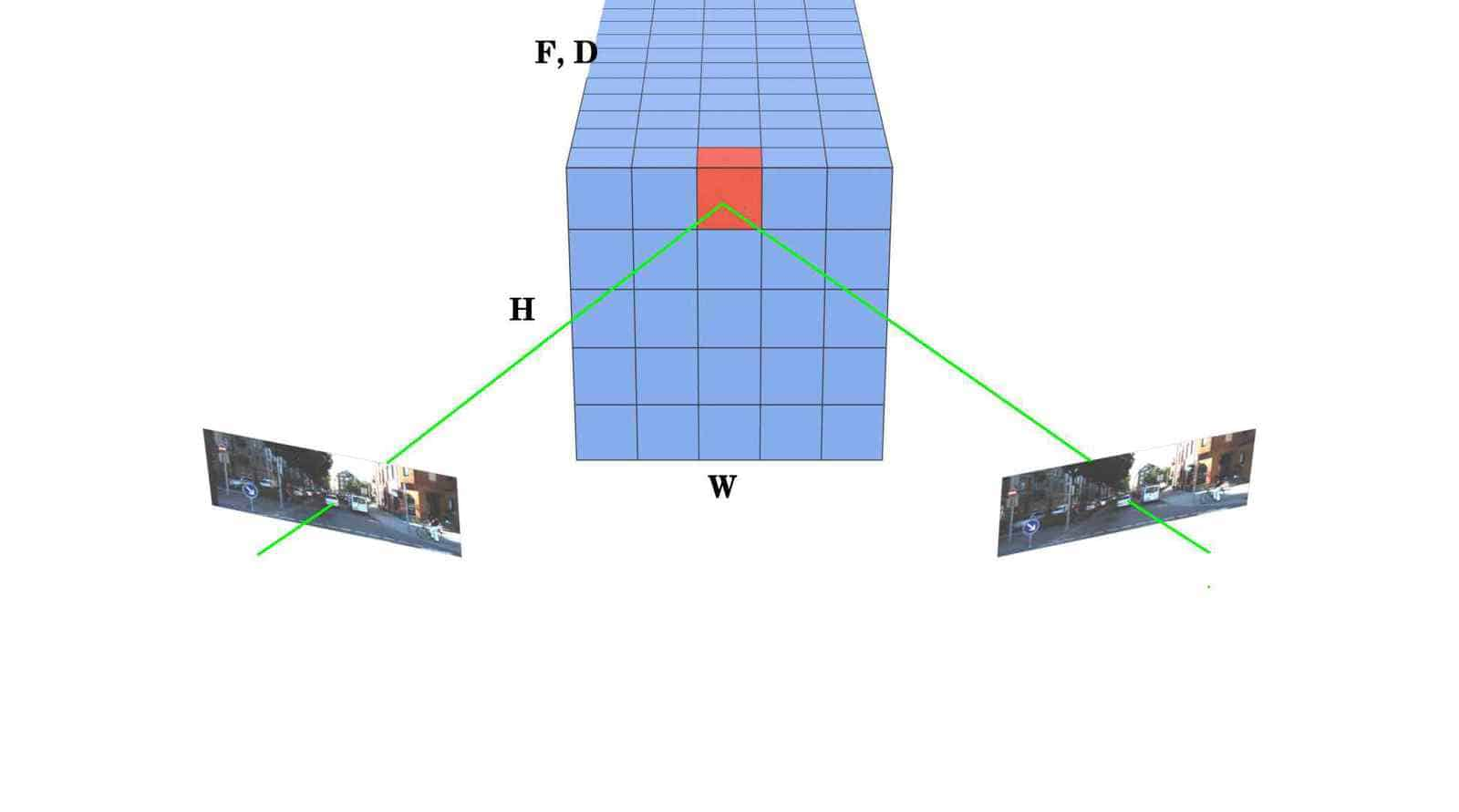 4D 的 cost volume 示意图
4D 的 cost volume 示意图
cost volume 是一个五维的张量,它存储了左右视图的特征和视差的匹配代价。具体来说:
当i=10时,代表视差为10像素,也就是说左图的某个像素点和右图的同一行上横坐标相差10的像素点匹配。 为了计算这种匹配的代价,需要从左右视图的特征中提取相应的部分,然后拼接起来,形成代价体积的一个切片。 左图的特征是一个32通道的张量,为了得到视差为10的切片,需要将左图的特征在x轴上向右平移10个像素,也就是说舍弃最左边的10列,保留剩下的部分。 右图的特征也是一个32通道的张量,为了得到视差为10的切片,需要将右图的特征在x轴上向左平移10个像素,也就是说舍弃最右边的10列,保留剩下的部分。 然后将左右视图的特征在通道维度上拼接起来,得到一个64通道的张量,这就是代价体积在视差为10时的切片。其他的视差也是类似的操作,只是平移的距离不同。 由于平移的过程中会丢失一些像素,所以代价体积的切片中会有一些空缺的地方,这些地方的值设为0,表示没有匹配的信息。 用一个for循环遍历所有可能的视差值,从0到最大视差除以4,因为特征图是原始图像的四分之一大小。 如果视差值大于0,就用切片操作从左右特征图中提取相应的部分,然后拼接到cost volume中。 cost volume 是一个五维的张量,第一个维度是batch size,第二个维度是通道数,第三个维度是视差值,第四个维度是高度,第五个维度是宽度。 cost[:, :refimg_fea.size()[1], i, :,i:] = refimg_fea[:,:,:,i:] 将左特征图在x轴上向右平移i个像素,然后赋值给cost volume的前32个通道,即左特征图的通道。 cost[:, refimg_fea.size()[1]:, i, :,i:] = targetimg_fea[:,:,:,:-i] 将右特征图在x轴上向左平移i个像素,然后赋值给cost volume的后32个通道,即右特征图的通道。 这样就完成了cost volume在视差为i时的切片,其他的视差也是类似的操作,只是平移的距离不同。 refimg_fea.size()[1]是左特征图的通道数,也就是32。这是因为左特征图是一个四维的张量,它的形状是[batch size, channel, height, width],所以refimg_fea.size()[1]就是取它的第二个维度的值,即通道数。右特征图的通道数也是一样的。 refimg_fea[:,:,:,i:]是Python中的切片(slicing)语法,它可以从一个序列(sequence)中提取出一部分元素,形成一个新的序列。切片的基本格式是: 序列[开始:结束:步长] 其中:
- 开始(start)是切片的起始位置,包含在切片中。如果省略,就默认从序列的开头开始。
- 结束(stop)是切片的终止位置,不包含在切片中。如果省略,就默认到序列的结尾结束。
- 步长(step)是切片的间隔,表示每隔多少个元素取一个。如果省略,就默认为1,表示连续取元素。
refimg_fea 是一个四维的张量(tensor),它的形状是[batch size, channel, height, width],表示一批图像的特征。refimg_fea[:,:,:,i:]的意思是:
- 在第一个维度上,取所有的元素,即所有的图像。
- 在第二个维度上,也取所有的元素,即所有的通道。
- 在第三个维度上,也取所有的元素,即所有的高度。
- 在第四个维度上,从第i个元素开始,到最后一个元素结束,步长为1,即在宽度上向右平移i个像素。
这样就得到了一个新的张量,它的形状是[batch size, channel, height, width-i],表示左特征图在x轴上向右平移i个像素后的结果。
targetimg_fea[:,:,:,:-i]中的-i表示从序列的结尾开始倒数第i个元素,也就是说,它是一个负数索引(negative index)。在Python中,可以用负数索引来从序列的右边开始访问元素,例如:
- 序列[-1]表示序列的最后一个元素。
- 序列[-2]表示序列的倒数第二个元素。
- 序列[-n]表示序列的倒数第n个元素。
所以,targetimg_fea[:,:,:,:-i]的意思是:
- 在第一个维度上,取所有的元素,即所有的图像。
- 在第二个维度上,也取所有的元素,即所有的通道。
- 在第三个维度上,也取所有的元素,即所有的高度。
- 在第四个维度上,从第0个元素开始,到倒数第i个元素结束,步长为1,即在宽度上向左平移i个像素。
这样就得到了一个新的张量,它的形状是[batch size, channel, height, width-i],表示右特征图在x轴上向左平移i个像素后的结果。
卷积层的参数量可以用以下公式计算:
1
参数量 = 卷积核大小 * 输入通道数 * 输出通道数
- 卷积核大小:卷积核的大小决定了卷积层可以提取的局部特征的大小。
- 输入通道数:输入通道数决定了卷积层可以处理的输入图像的通道数。
- 输出通道数:输出通道数决定了卷积层的输出特征图的通道数。
Disparity Regression
PSMNet使用一个3D Out层来对成本体积进行视差回归。3D Out层使用一个3D卷积核来将成本体积的通道数降到1,然后使用一个SoftArgMin操作来计算每个像素的视差值。SoftArgMin操作是一种软化的最小值搜索,它可以根据成本体积中的概率分布来加权平均所有可能的视差值,从而得到一个连续的视差图。
为什么要用多个堆叠的hourglass网络来构建PSM-Net?
用多个堆叠的hourglass网络来构建PSM-Net的原因是为了利用多尺度的特征来进行立体匹配,从而提高视差估计的精度和鲁棒性1。
- hourglass网络是一种沙漏型的结构,由自底向上和自顶向下的过程组成,能够捕获不同分辨率下的图像信息,并通过跨层连接来融合特征2。
- 堆叠的hourglass网络是由多个hourglass模块串联而成的,每个模块的输出都作为下一个模块的输入,这样可以在整个图像上重新估计姿态和特征,并利用中间监督来增强学习效果3。
- hourglass网络最初是用于人体姿势估计的任务,通过预测每个像素上存在人体关键点的概率来定位人体姿势4。
Result
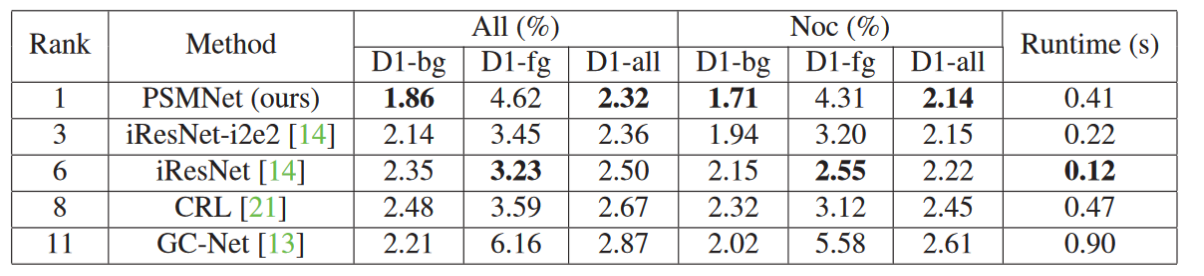
Comments
开创性的应用了 pyramid 结构,通过堆叠沙漏网络,将上下文信息进行聚合,并使用堆叠的沙漏网络进行特征提取,最后通过3D CNN 进行特征融合。 Github 1.3K Star
GC-Net: End-to-End Learning of Geometry and Context for Deep Stereo Regression
Info
Date
2017/11
Conference/Publication
2017 IEEE International Conference on Computer Vision (ICCV)
Author
Alex Kendall, Hayk Martirosyan, Saumitro Dasgupta, Peter Henry, Ryan Kennedy Abraham, Bachrach Adam Bry Skydio Research
Contributions
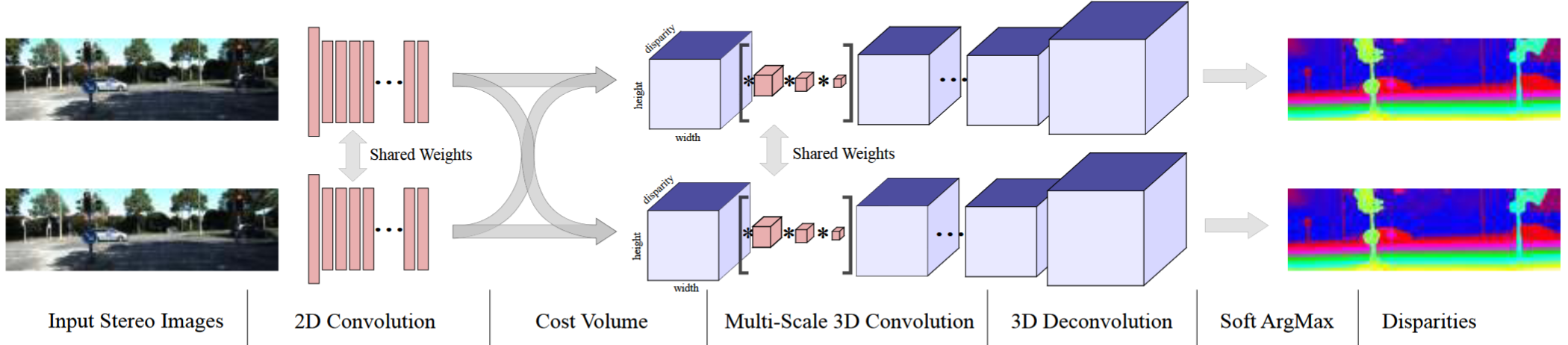 创新性地提出了一种新颖的深度学习架构,用于从一对校正后的立体图像中回归视差。我们利用问题几何的知识,使用深度特征表示来形成成本量。我们学习在这个体积上使用 3-D 卷积来合并上下文信息。使用建议的可微分软 argmin 运算从成本量中回归视差值,这使我们能够端到端地训练我们的方法达到亚像素精度,而无需任何额外的后处理或正则化。
创新性地提出了一种新颖的深度学习架构,用于从一对校正后的立体图像中回归视差。我们利用问题几何的知识,使用深度特征表示来形成成本量。我们学习在这个体积上使用 3-D 卷积来合并上下文信息。使用建议的可微分软 argmin 运算从成本量中回归视差值,这使我们能够端到端地训练我们的方法达到亚像素精度,而无需任何额外的后处理或正则化。
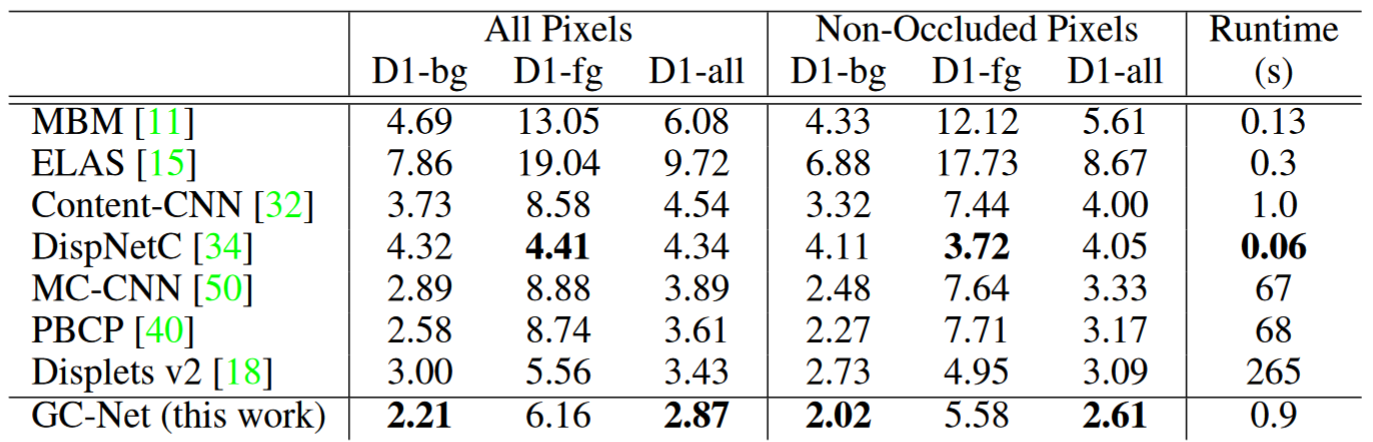
Result
A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation
Info
Date
2016/06
Conference/Publication
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Author
ikolaus Mayer∗1, Eddy Ilg∗1, Philip H ̈ ausser∗2, Philipp Fischer∗1† 1University of Freiburg 2Technical University of Munich
Contributions
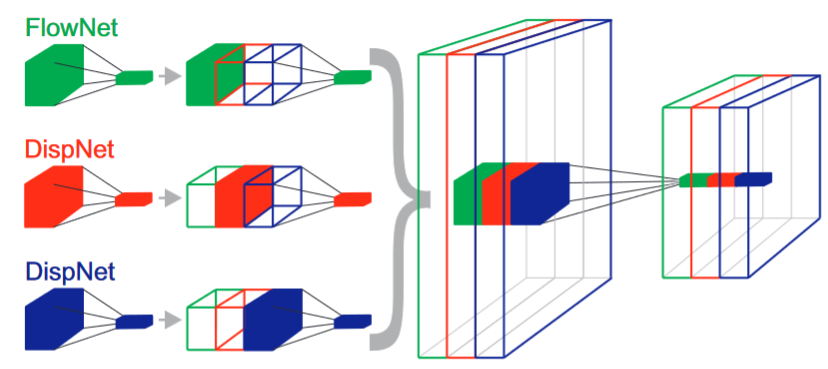 这篇论文提出了一种利用卷积网络进行视差和场景流估计的方法,实现了实时和高精度的结果。 方法:这篇论文使用了一个端到端的卷积网络,可以同时输出视差图和光流图,然后通过一个后处理模块将它们结合成场景流图。
这篇论文提出了一种利用卷积网络进行视差和场景流估计的方法,实现了实时和高精度的结果。 方法:这篇论文使用了一个端到端的卷积网络,可以同时输出视差图和光流图,然后通过一个后处理模块将它们结合成场景流图。
Result
Feature match
SuperGlue: Learning Feature Matching With Graph Neural Networks
Info
Date
2020/06
Conference/Publication
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Author
Paul-Edouard Sarlin1, Daniel DeTone2, Tomasz Malisiewicz2, Andrew Rabinovich2 1 ETH Zurich 2 Magic Leap, Inc.
Contributions
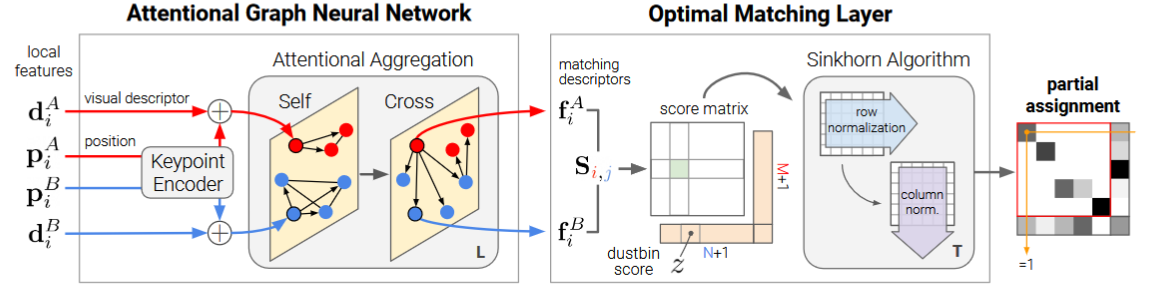 与传统的手工设计的启发式方法相比,SuperGlue 通过图像对的端到端训练来学习 3D 世界的几何变换和规律性的先验知识。 SuperGlue 通过共同寻找对应点并拒绝不可匹配的点来匹配两组局部特征。通过解决可微的最优传输问题来估计分配,其成本由图神经网络预测。我引入了一种基于注意力的灵活上下文聚合机制,使 SuperGlue 能够联合推理底层 3D 场景和特征分配。
与传统的手工设计的启发式方法相比,SuperGlue 通过图像对的端到端训练来学习 3D 世界的几何变换和规律性的先验知识。 SuperGlue 通过共同寻找对应点并拒绝不可匹配的点来匹配两组局部特征。通过解决可微的最优传输问题来估计分配,其成本由图神经网络预测。我引入了一种基于注意力的灵活上下文聚合机制,使 SuperGlue 能够联合推理底层 3D 场景和特征分配。
Result
SuperGlue 的性能优于其他学习方法,并在具有挑战性的现实室内和室外环境中的姿态估计任务中取得了最先进的结果。
精度: 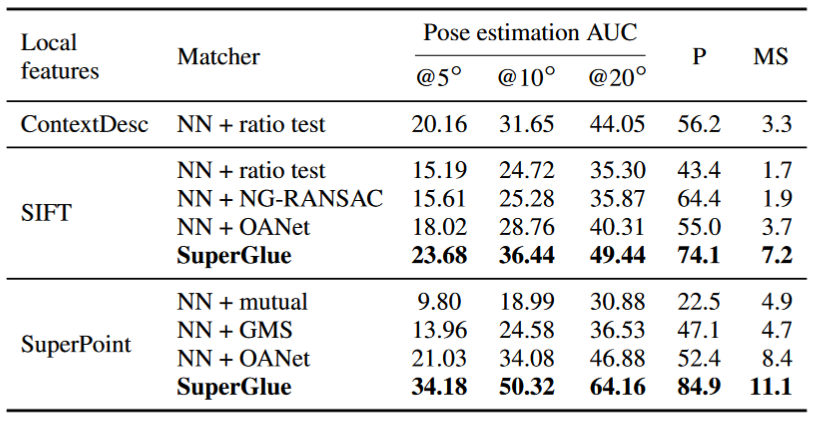 速度: 69 ms/15 FPS (1080 GPU)
速度: 69 ms/15 FPS (1080 GPU)
Comments
https://blog.csdn.net/weixin_42730997/article/details/108562592 SuperGlue对于匹配问题的新看法,是用一个经典的数学问题来定义,即最优运输问题(Optimal Transport)。
LightGlue: Local Feature Matching at Light Speed
Info
Date
2023
Conference/Publication
2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Author
Philipp Lindenberger1, Paul-Edouard Sarlin1 Marc Pollefeys1,2 1 ETH Zurich 2 Microsoft Mixed Reality & AI Lab
Contributions
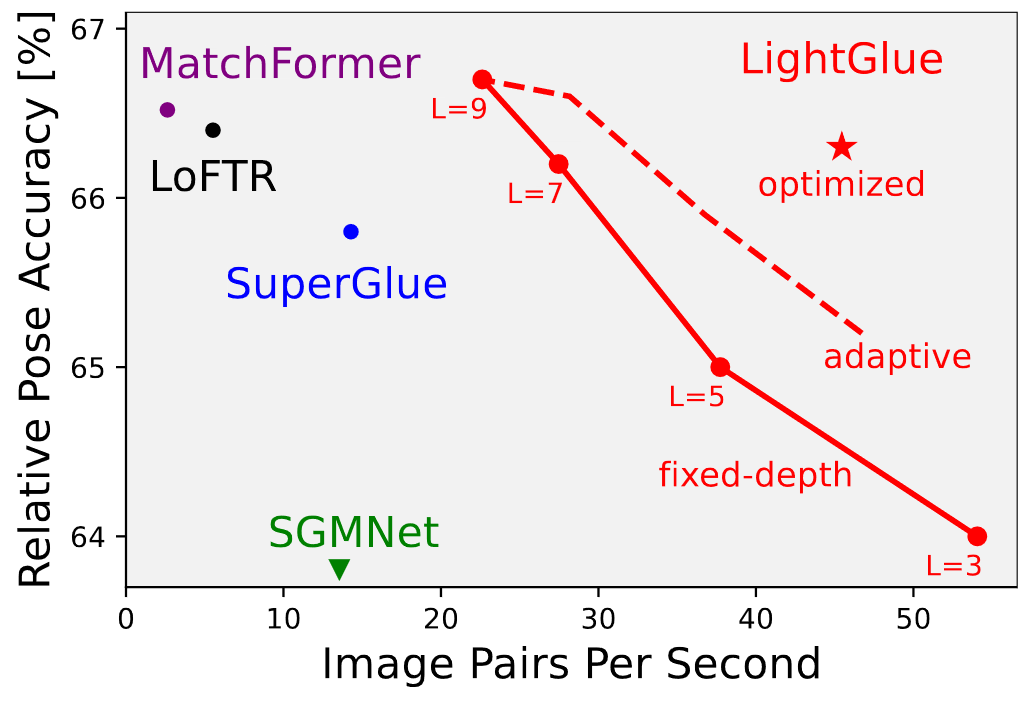
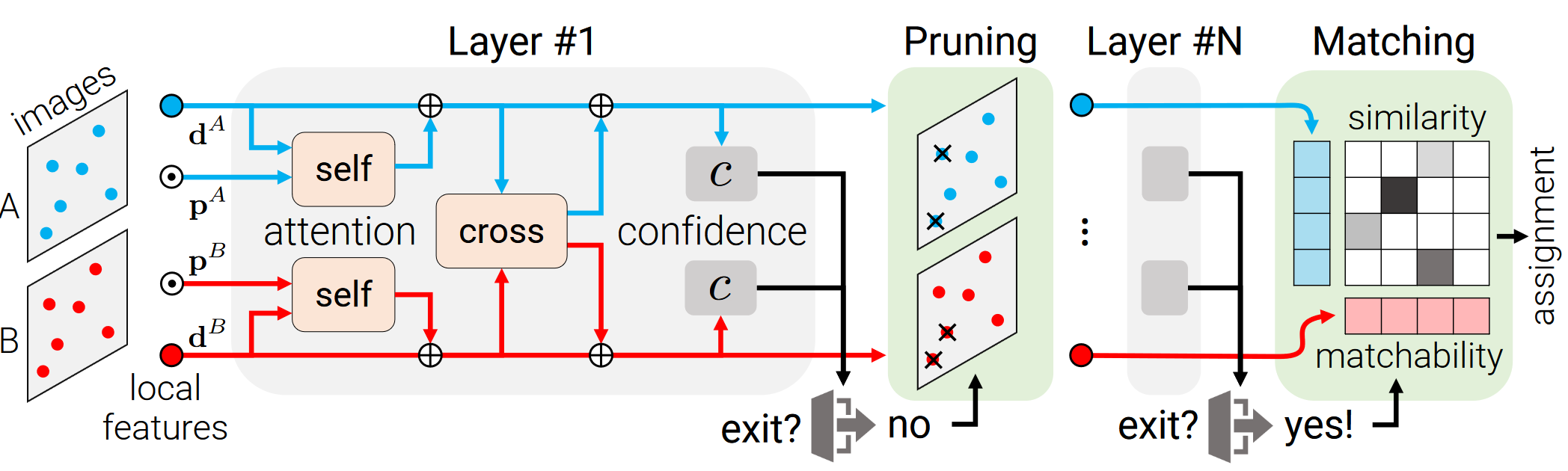 论文重新审视了SuperGlue的多个设计决策,这是稀疏匹配领域的最新技术,并得出了简单但有效的改进方法。这些改进使得LightGlue在内存和计算方面更加高效,更准确,并且更容易训练。其中一个关键特性是LightGlue对问题的难度是自适应的:对于直观上易于匹配的图像对,例如具有更大的视觉重叠或有限的外观变化,推理速度更快。 在准确性、效率和训练易用性方面优于现有的SuperGlue。通过对架构进行简单而有效的修改,提出了训练高性能深度特征匹配器的方法。 LightGlue具有自适应的特性,可以根据图像对的难度进行灵活调整。通过预测对应关系并允许模型自省,可以在易于匹配的图像对上实现更快的推理速度,而在具有挑战性的图像对上仍然保持准确性。 LightGlue的应用前景广阔,特别适用于对延迟敏感的应用,如SLAM和基于众包数据的更大场景重建。
论文重新审视了SuperGlue的多个设计决策,这是稀疏匹配领域的最新技术,并得出了简单但有效的改进方法。这些改进使得LightGlue在内存和计算方面更加高效,更准确,并且更容易训练。其中一个关键特性是LightGlue对问题的难度是自适应的:对于直观上易于匹配的图像对,例如具有更大的视觉重叠或有限的外观变化,推理速度更快。 在准确性、效率和训练易用性方面优于现有的SuperGlue。通过对架构进行简单而有效的修改,提出了训练高性能深度特征匹配器的方法。 LightGlue具有自适应的特性,可以根据图像对的难度进行灵活调整。通过预测对应关系并允许模型自省,可以在易于匹配的图像对上实现更快的推理速度,而在具有挑战性的图像对上仍然保持准确性。 LightGlue的应用前景广阔,特别适用于对延迟敏感的应用,如SLAM和基于众包数据的更大场景重建。
Result
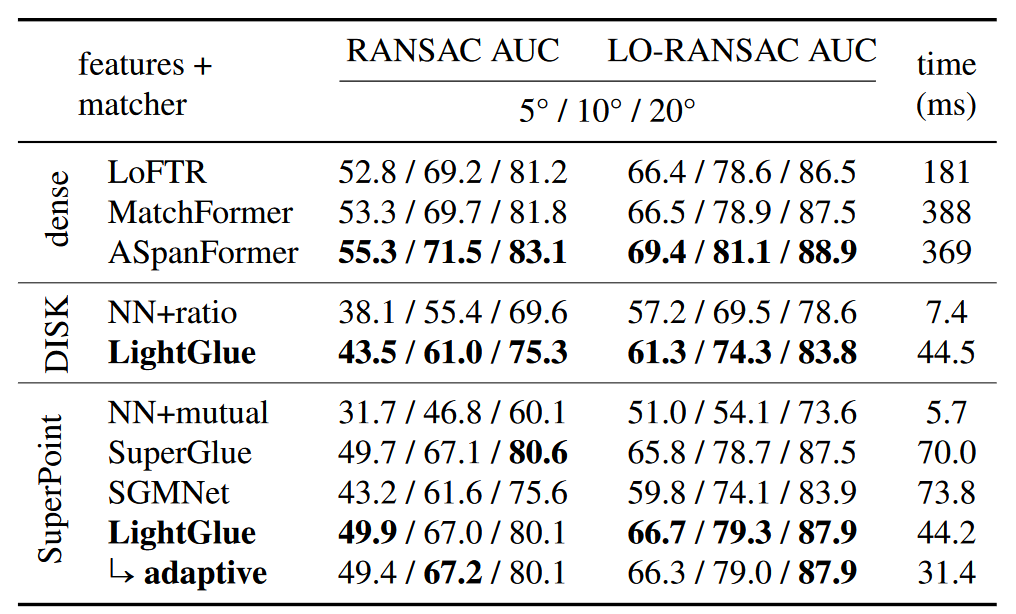
Comments
https://zhuanlan.zhihu.com/p/642459384 匹配稀疏的局部特征。借鉴了SuperGlue的成功,论文将注意力机制的能力与匹配问题的见解以及Transformer的最新创新相结合。论文赋予这个模型自省其预测的置信度的能力。这产生了一种优雅的方案,根据每对图像的难度自适应计算量。模型的深度和宽度都是自适应的:1)如果所有预测都已准备好,推理可以在较早的层停止;2)被认为不可匹配的点从进一步的步骤中提前丢弃。最终得到的模型LightGlue比传统的SuperGlue更快、更准确,并且更容易训练。
LoFTR: Detector-Free Local Feature Matching with Transformers
Info
Date
2021/06
Conference/Publication
2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Author
Jiaming Sun1,2 Zehong Shen1, Yuang Wang1, Hujun Bao1 Xiaowei Zhou1† 1Zhejiang University, 2SenseTime Research
Contributions
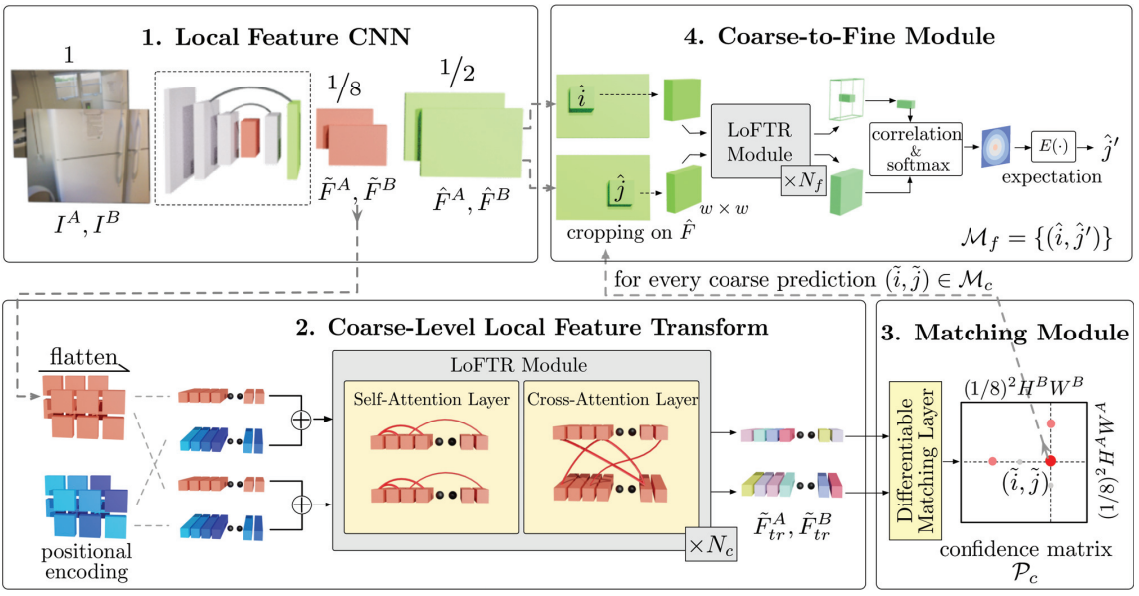 文章提出了一种新颖的用于局部图像特征匹配的方法。代替了传统的顺序执行图像特征检测,描述和匹配的步骤,本文提出首先在粗粒度上建立逐像素的密集匹配,然后在精粒度上完善精修匹配的算法。与使用cost volume搜索对应关系的稠密匹配方法相比,本文使用了Transformers中的使用自我和交叉注意力层(self and cross attention layers)来获取两个图像的特征描述符。Transformers提供的全局感受野使图像能够在弱纹理区域产生密集匹配(通常情况下在低纹理区域,特征检测器通常难以产生可重复的特征点)。在室内和室外数据集上进行的实验表明,LoFTR在很大程度上优于现有技术
文章提出了一种新颖的用于局部图像特征匹配的方法。代替了传统的顺序执行图像特征检测,描述和匹配的步骤,本文提出首先在粗粒度上建立逐像素的密集匹配,然后在精粒度上完善精修匹配的算法。与使用cost volume搜索对应关系的稠密匹配方法相比,本文使用了Transformers中的使用自我和交叉注意力层(self and cross attention layers)来获取两个图像的特征描述符。Transformers提供的全局感受野使图像能够在弱纹理区域产生密集匹配(通常情况下在低纹理区域,特征检测器通常难以产生可重复的特征点)。在室内和室外数据集上进行的实验表明,LoFTR在很大程度上优于现有技术
Result
116 ms for a 640×480 image pair on an RTX 2080Ti. 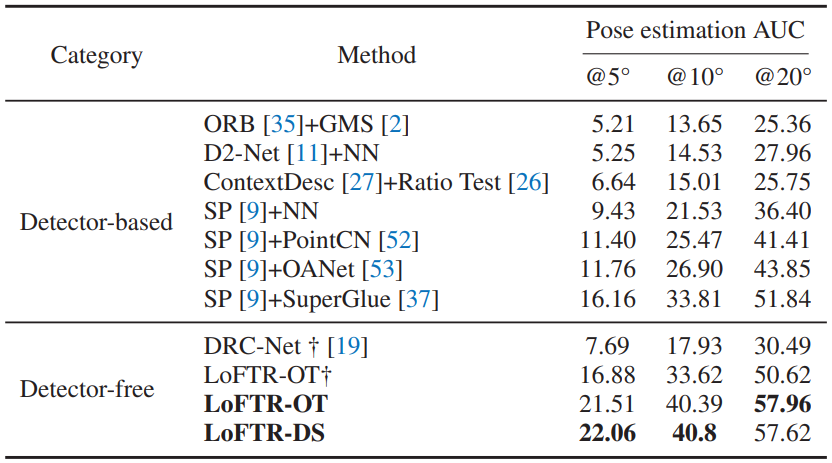
Comments
Event-based stereo
Unsupervised Deep Event Stereo for Depth Estimation
Info
Date
2022/11
Conference/Publication
IEEE Transactions on Circuits and Systems for Video Technology(TCSVT) CCF-B, Q2
Author
S. M. Nadim Uddin, Soikat Hasan Ahmed , and Yong Ju Jung School of Computing, Gachon University, Seongnam-si, South Korea, #551-600 in QS
Contributions
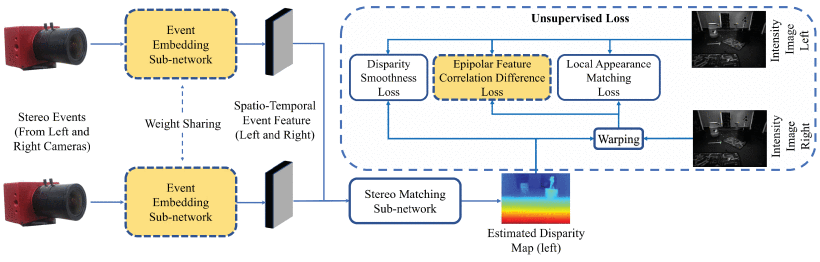 提出了第一个无监督的事件立体匹配方法,可以预测稠密的视差图,并通过将深度估计问题转化为基于变形的重建问题进行训练 创新:提出了一种新颖的无监督损失函数,使网络最小化真实强度图像和变形图像之间的特征级别的极线相关性差异;提出了一种新颖的事件嵌入机制,利用时空邻近事件来捕捉事件之间的时空关系,用于立体匹配
提出了第一个无监督的事件立体匹配方法,可以预测稠密的视差图,并通过将深度估计问题转化为基于变形的重建问题进行训练 创新:提出了一种新颖的无监督损失函数,使网络最小化真实强度图像和变形图像之间的特征级别的极线相关性差异;提出了一种新颖的事件嵌入机制,利用时空邻近事件来捕捉事件之间的时空关系,用于立体匹配
Result
精度:实验结果表明,该方法在没有真实视差图的情况下,显著优于基准的无监督方法(例如,最高提高了16.88%),并且与现有的有监督方法达到了可比较的结果  速度:73.69ms/13.56FPS
速度:73.69ms/13.56FPS 
Comments
首个无监督的深度估计方法,通过事件嵌入来捕捉事件之间的时空关系,从而提高立体匹配的性能
Stereo Depth from Events Cameras: Concentrate and Focus on the Future
Info
Date
2022/06
Conference/Publication
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Author
Yeongwoo Nam1,2,Mohammad Mostafavi3, Kuk-Jin Yoon4 Jonghyun Choi2,5,† 1Saige Research 2NAVER AI Lab. 3Lunit 4KAIST 5Yonsei University
Contributions
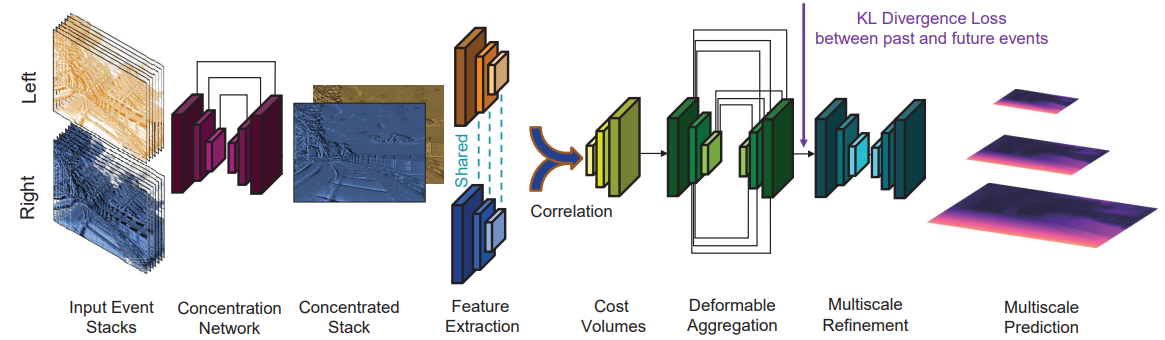 本文的方法通过一个基于注意力的网络和一个从未来事件中知识蒸馏的方案,学习专注于密集的事件,从而产生一个具有高细节的事件表示,用于深度估计。本文的方法还通过一个分层的事件和 intensity 组合网络,将 intensity 与事件结合起来,以实现更好的深度估计。
本文的方法通过一个基于注意力的网络和一个从未来事件中知识蒸馏的方案,学习专注于密集的事件,从而产生一个具有高细节的事件表示,用于深度估计。本文的方法还通过一个分层的事件和 intensity 组合网络,将 intensity 与事件结合起来,以实现更好的深度估计。
Result
FPS is reported for two input resolutions: 346 × 260: 11.3 FPS 640 × 480: 23.2 FPS 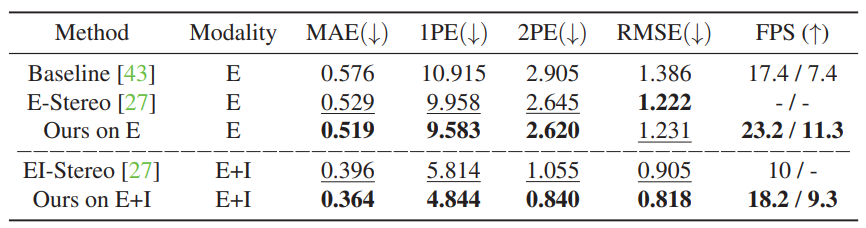
Comments
Selection and Cross Similarity for Event-Image Deep Stereo
Info
Date
2022
Conference/Publication
ECCV
Author
Hoonhee Cho and Kuk-Jin Yoon Korea Advanced Institute of Science and Technology
Contributions
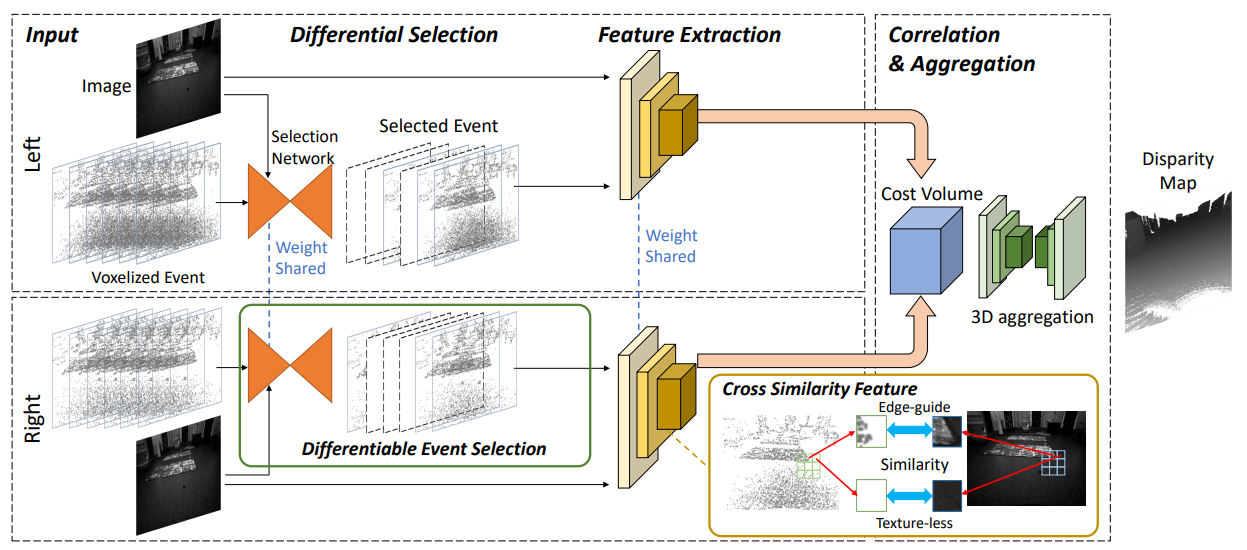 文章提出了一种利用事件相机和帧相机的深度估计方法,能够在光照和运动条件复杂的场景中获得高质量的深度图。本文的创新点是提出了一个可微分的事件选择网络,用于选择最相关的事件,以及一个邻域交叉相似性特征,用于考虑事件和图像之间的不同模态的相似性。事件选择网络和邻域交叉相似性特征。事件选择网络是一个基于注意力机制的网络,用于从事件流中选择最有利于深度估计的事件。邻域交叉相似性特征是一种基于卷积神经网络的特征,用于计算事件和图像之间的相似性,并结合到 cost volume 中,以提高深度估计的精度。
文章提出了一种利用事件相机和帧相机的深度估计方法,能够在光照和运动条件复杂的场景中获得高质量的深度图。本文的创新点是提出了一个可微分的事件选择网络,用于选择最相关的事件,以及一个邻域交叉相似性特征,用于考虑事件和图像之间的不同模态的相似性。事件选择网络和邻域交叉相似性特征。事件选择网络是一个基于注意力机制的网络,用于从事件流中选择最有利于深度估计的事件。邻域交叉相似性特征是一种基于卷积神经网络的特征,用于计算事件和图像之间的相似性,并结合到 cost volume 中,以提高深度估计的精度。
Result

Comments
论文没有提到速度,需要自己验证。但是没有提供 pre-trained model.
Event-Intensity Stereo: Estimating Depth by the Best of Both Worlds
Info
Date
2021/10
Conference/Publication
2021 IEEE/CVF International Conference on Computer Vision (ICCV)
Author
S. Mohammad Mostafavi I.§ GIST, South Korea Kuk-Jin Yoon KAIST, South Korea Jonghyun Choi GIST, South Korea
Contributions
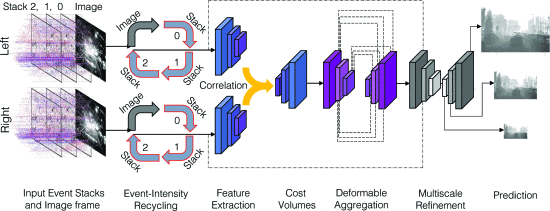 提出了一种结合事件相机和传统相机的立体深度估计方法,能够在不同的场景和条件下,预测准确的深度值,具有高效、鲁棒和灵活的特点。 方法:这篇论文设计了一个端到端的神经网络模型,将事件和图像按顺序结合并进行相关性分析,利用事件的时间信息和图像的空间信息,生成稠密的视差图。
提出了一种结合事件相机和传统相机的立体深度估计方法,能够在不同的场景和条件下,预测准确的深度值,具有高效、鲁棒和灵活的特点。 方法:这篇论文设计了一个端到端的神经网络模型,将事件和图像按顺序结合并进行相关性分析,利用事件的时间信息和图像的空间信息,生成稠密的视差图。
Result
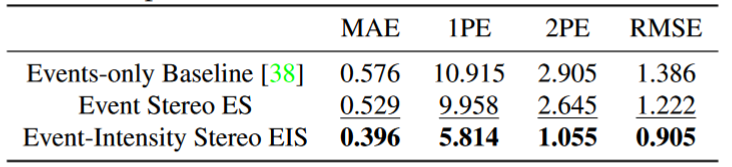 near 10 FPS inference time using an NVIDIA RTX 2080 Ti GPU
near 10 FPS inference time using an NVIDIA RTX 2080 Ti GPU
Comments
结合了事件相机和传统相机,速度较慢
Deep Event Stereo Leveraged by Event-to-Image Translation
Info
Date
2021/05
Conference/Publication
The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21)
Author
Soikat Hasan Ahmed, Hae Woong Jang, S M Nadim Uddin, Yong Ju Jung† College of Information Technology Convergence, Gachon University, Seongnam, South Korea
Contributions
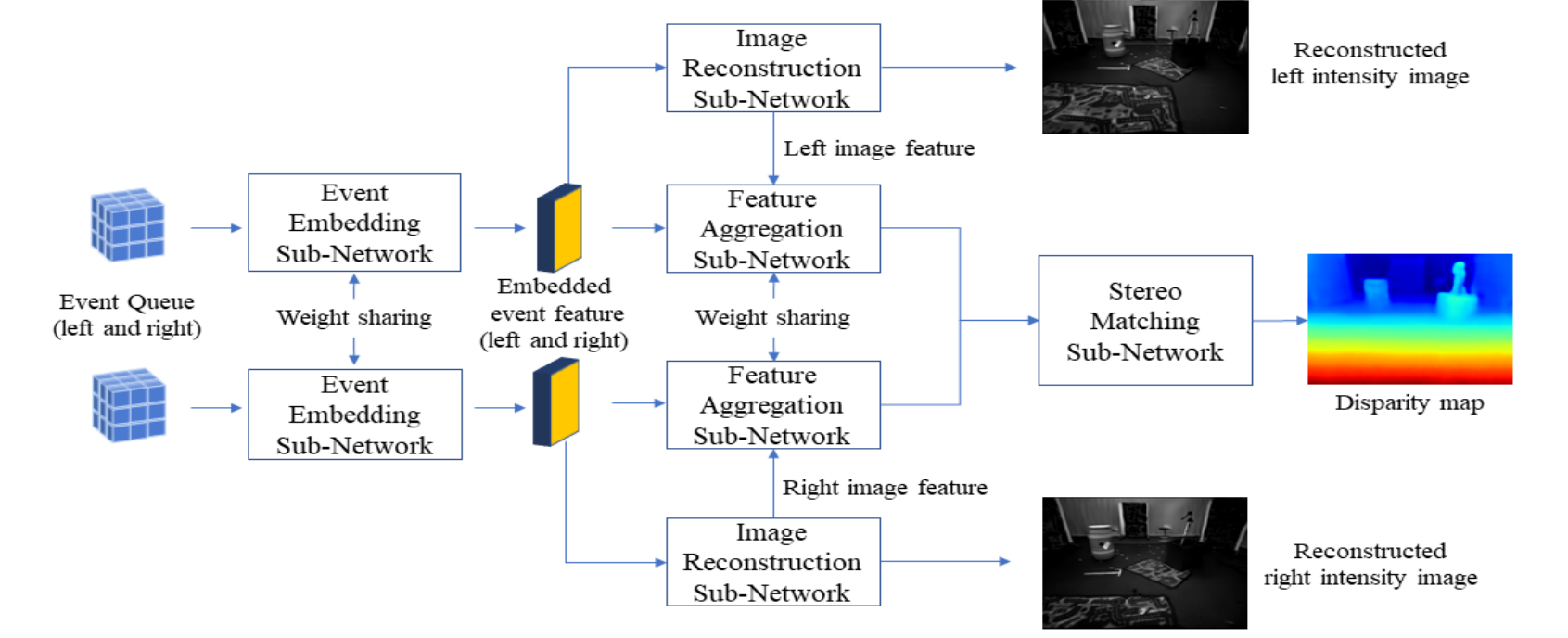 这篇论文提出了一种新的端到端的深度事件立体网络,可以从嵌入的事件数据中重建空间图像特征,并利用重建的图像特征来增强事件特征,从而计算出稠密的视差图。这是一种利用事件到图像转换的深度事件立体方法。 方法:这篇论文引入了一种新的图像重建子网络,使用了交叉语义注意力机制,以及一种特征聚合子网络,使用了堆叠的扩张空间自适应去归一化机制。
这篇论文提出了一种新的端到端的深度事件立体网络,可以从嵌入的事件数据中重建空间图像特征,并利用重建的图像特征来增强事件特征,从而计算出稠密的视差图。这是一种利用事件到图像转换的深度事件立体方法。 方法:这篇论文引入了一种新的图像重建子网络,使用了交叉语义注意力机制,以及一种特征聚合子网络,使用了堆叠的扩张空间自适应去归一化机制。
We found that the frame-based stereo matching method show worse results than the current method (i.e. 12.2 vs 11.3 for mean depth error). This is due to the frame-based methods generally require comparatively larger datasets and consist of more training parameters, which lead to requiring more training for convergence.
Result
这篇论文在多车辆立体事件相机数据集(MVSEC)上评估了所提出的方法,并显示了它在稀疏和稠密视差估计场景下都优于现有的方法。 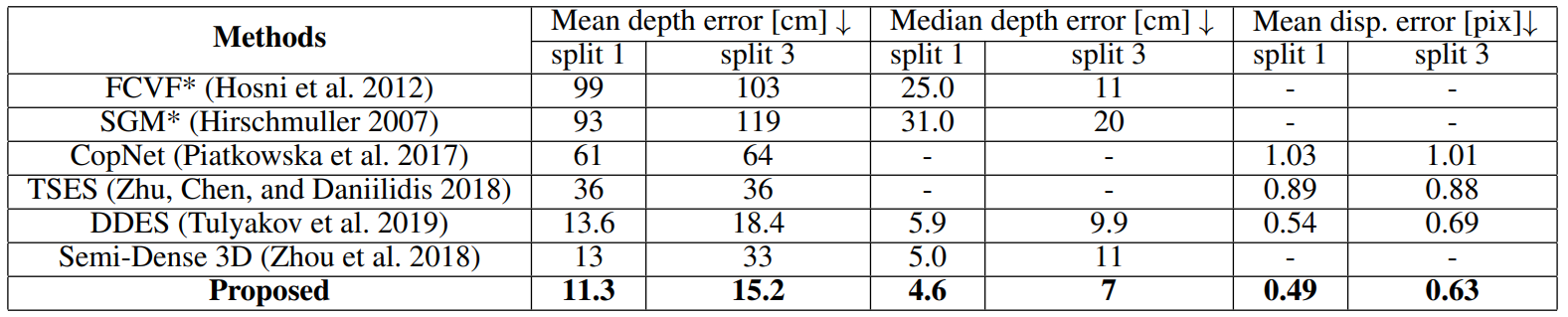
Comments
没有提到速度指标
Learning an Event Sequence Embedding for Dense Event-Based Deep Stereo
Info
Date
2019/10
Conference/Publication
2019 IEEE/CVF International Conference on Computer Vision (ICCV)
Author
Stepan Tlakovsky Space Engineering Center at ́ Ecole Polytechnique F ́ ed ́ erale de Lausanne
Contributions
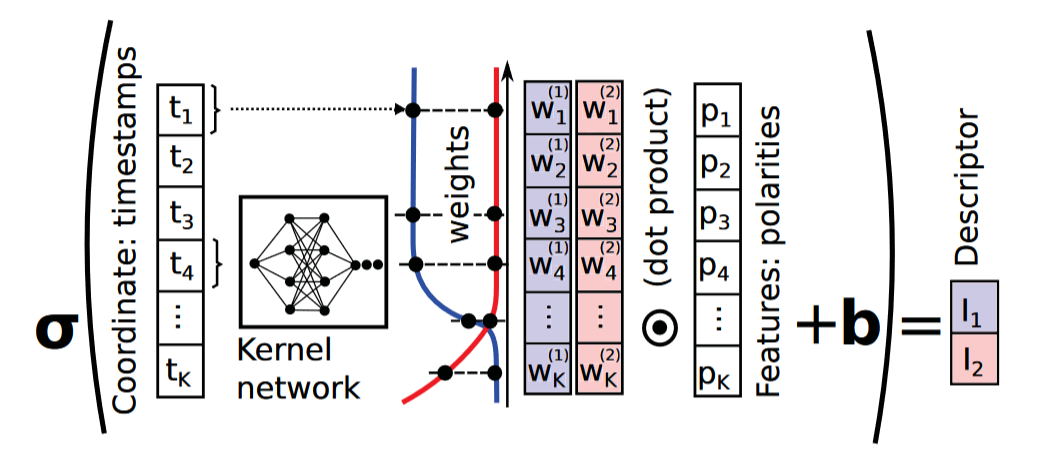 事件序列嵌入模块:这是一个新的模块,用于处理异步事件序列,因为传统的算法只能处理同步的、空间网格化的数据。该模块通过首先使用一种新颖的全连接层在不规则采样的连续域上沿时间方向聚合信息,然后在离散的空间域上聚合信息,来构建事件序列的表示。 基于深度学习的立体视觉方法:这是一种基于事件驱动相机的立体视觉方法,是第一种基于学习的方法,也是唯一一种能够产生稠密结果的方法。该方法在多车辆立体事件相机数据集(MVSEC)上表现出了很大的性能提升,该数据集已经成为事件驱动立体视觉方法的标准评测集。
事件序列嵌入模块:这是一个新的模块,用于处理异步事件序列,因为传统的算法只能处理同步的、空间网格化的数据。该模块通过首先使用一种新颖的全连接层在不规则采样的连续域上沿时间方向聚合信息,然后在离散的空间域上聚合信息,来构建事件序列的表示。 基于深度学习的立体视觉方法:这是一种基于事件驱动相机的立体视觉方法,是第一种基于学习的方法,也是唯一一种能够产生稠密结果的方法。该方法在多车辆立体事件相机数据集(MVSEC)上表现出了很大的性能提升,该数据集已经成为事件驱动立体视觉方法的标准评测集。
Result
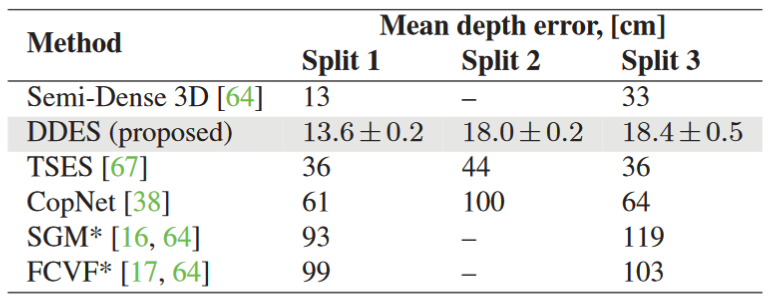 Our implementation of DDES runs at about 10 frames per second on a desktop PC with a GeForce GTX TITAN X GPU
Our implementation of DDES runs at about 10 frames per second on a desktop PC with a GeForce GTX TITAN X GPU
Unsupervised Event-Based Learning of Optical Flow, Depth, and Egomotion
Info
Date
2019/10
Conference/Publication
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Author
Alex Zihao Zhu, Liangzhe Yuan, Kenneth Chaney, Kostas Daniilidis University of Pennsylvania
Contributions
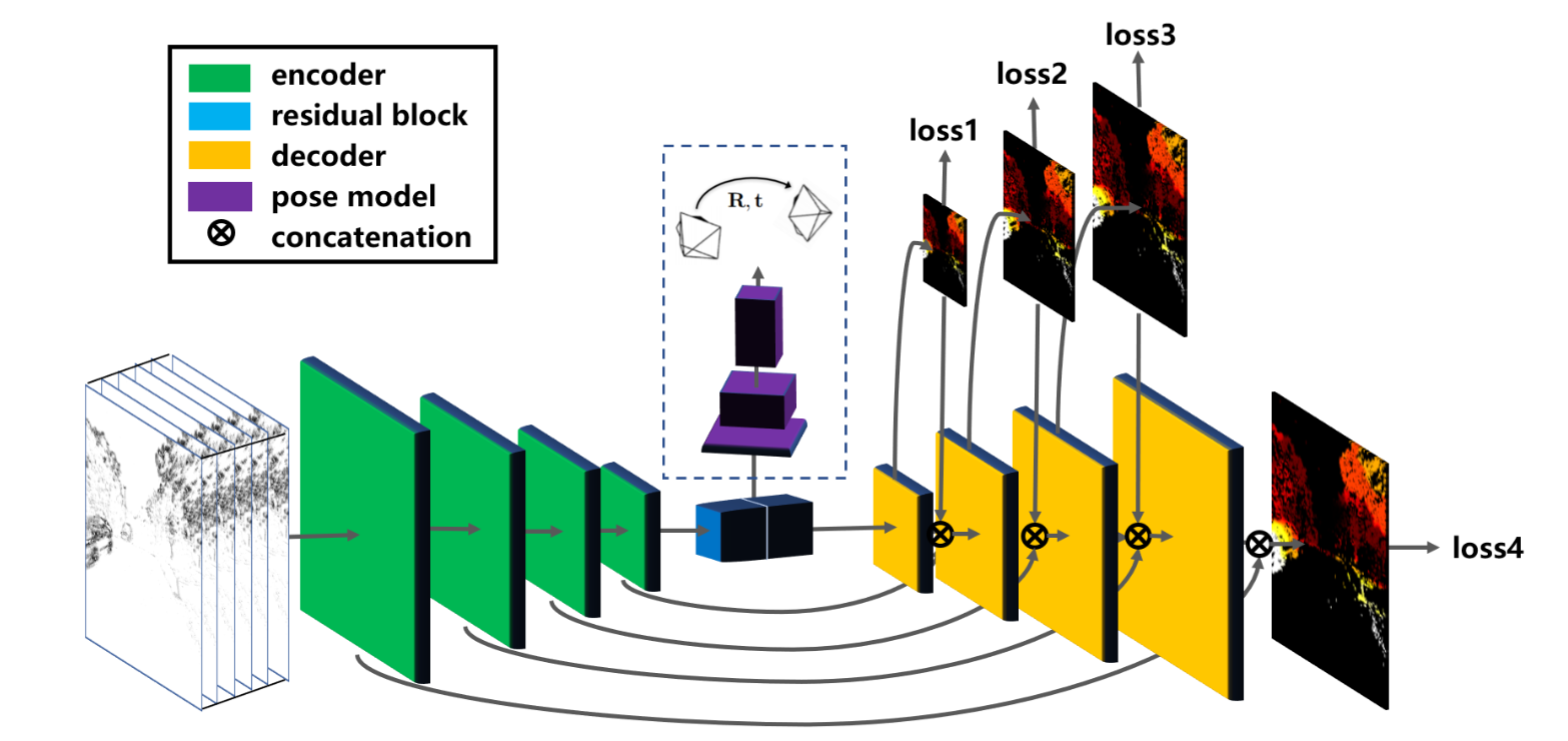 Network architecture for both the optical flow and egomotion and depth networks 事件摄像机无监督学习的新颖框架,该框架仅从事件流中学习运动信息。特别是,我们提出了以离散量的形式输入事件的表示,该表示保持事件的时间分布,我们通过神经网络来预测事件的运动。此运动用于尝试消除事件图像中的任何运动模糊。然后,我们提出应用于运动补偿事件图像的损失函数,以测量该图像中的运动模糊。我们使用该框架训练两个网络,一个用于预测光流,一个用于预测自我运动和深度,并在多车辆立体事件相机数据集上评估这些网络,以及来自各种不同场景的定性结果
Network architecture for both the optical flow and egomotion and depth networks 事件摄像机无监督学习的新颖框架,该框架仅从事件流中学习运动信息。特别是,我们提出了以离散量的形式输入事件的表示,该表示保持事件的时间分布,我们通过神经网络来预测事件的运动。此运动用于尝试消除事件图像中的任何运动模糊。然后,我们提出应用于运动补偿事件图像的损失函数,以测量该图像中的运动模糊。我们使用该框架训练两个网络,一个用于预测光流,一个用于预测自我运动和深度,并在多车辆立体事件相机数据集上评估这些网络,以及来自各种不同场景的定性结果
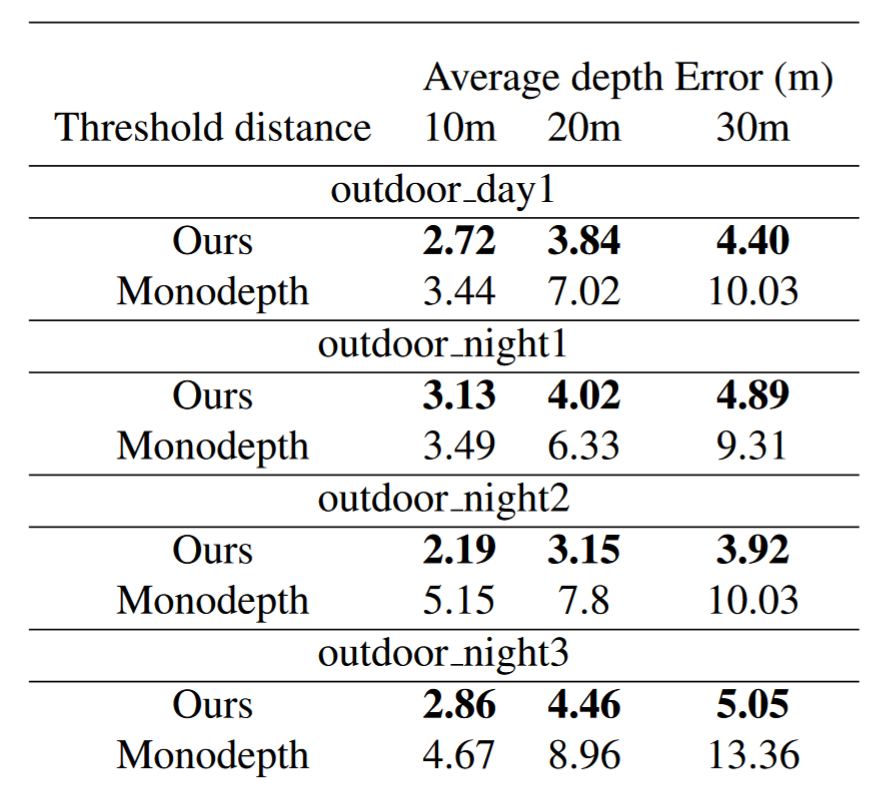
Result
Realtime Time Synchronized Event-Based Stereo
Info
Date
2018
Conference/Publication
ECCV
Author
Alex Zihao Zhu, Yibo Chen, and Kostas Daniilidis University of Pennsylvania
Contributions
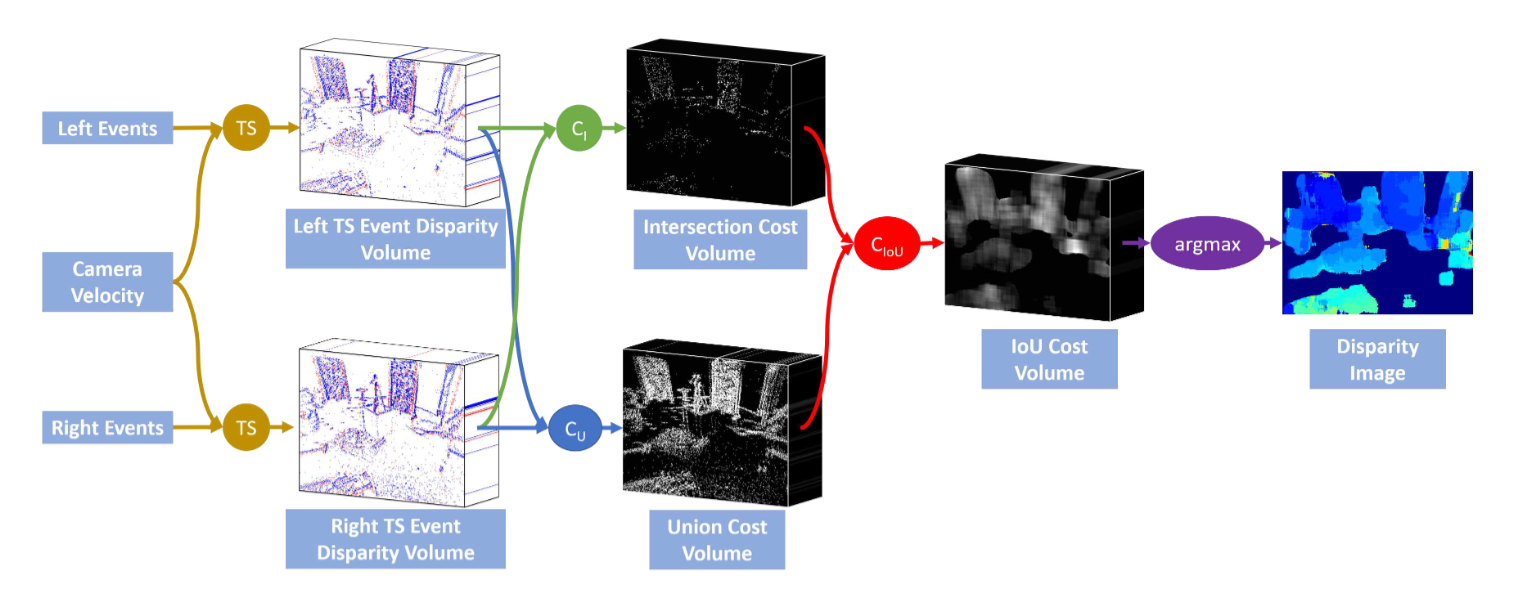 在这项工作中,我们提出了一种新颖的基于事件的立体方法,该方法解决了移动事件相机的运动模糊问题。我们的方法使用相机的速度和一系列差异来同步事件的位置,就好像它们是在单个时间点捕获的一样。我们使用一对新颖的时间同步事件视差体积来表示这些事件,我们展示了它们消除了体积中正确视差处的像素的运动模糊,同时进一步模糊了错误视差处的像素。然后,我们在这些时间同步的事件视差体积上应用一种新颖的匹配成本,这既奖励体积之间的相似性,又惩罚模糊性。通过对多车辆立体事件相机数据集进行评估,我们表明我们的方法优于更昂贵的基于平滑的事件立体方法。
在这项工作中,我们提出了一种新颖的基于事件的立体方法,该方法解决了移动事件相机的运动模糊问题。我们的方法使用相机的速度和一系列差异来同步事件的位置,就好像它们是在单个时间点捕获的一样。我们使用一对新颖的时间同步事件视差体积来表示这些事件,我们展示了它们消除了体积中正确视差处的像素的运动模糊,同时进一步模糊了错误视差处的像素。然后,我们在这些时间同步的事件视差体积上应用一种新颖的匹配成本,这既奖励体积之间的相似性,又惩罚模糊性。通过对多车辆立体事件相机数据集进行评估,我们表明我们的方法优于更昂贵的基于平滑的事件立体方法。
Result
takes 40ms to run on a laptop NVIDIA 960M GPU