备忘录
本文是一个摘抄性质的备忘录,若有侵权,请联系我删除。
包含 AI 生成的内容,不保证准确性。
双目匹配
双目立体匹配步骤详解 - 李迎松的文章 1.匹配代价计算 2.代价聚合 3.视差计算 4.视差优化
极线约束
Epipolar line: $x_L e_L$ and $x_R e_L$ 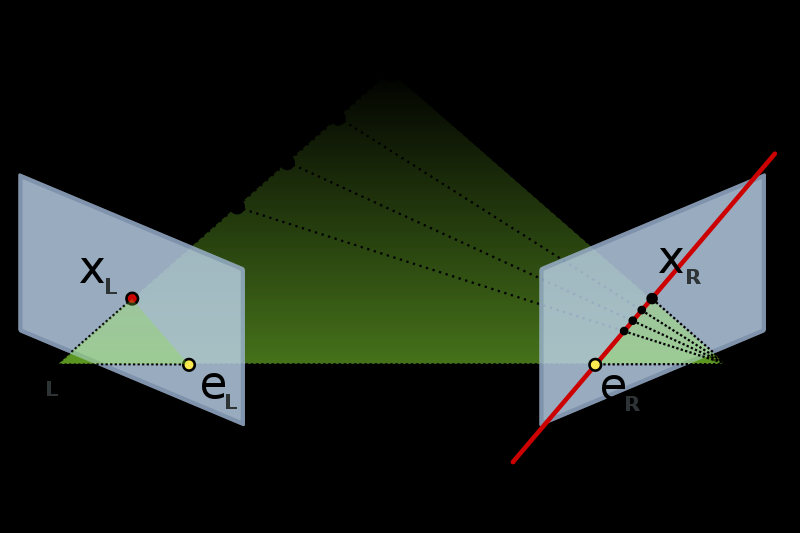 Wikipedia: Epipolar geometry
Wikipedia: Epipolar geometry
DSI
 https://blog.csdn.net/tfb760/article/details/108074764
https://blog.csdn.net/tfb760/article/details/108074764
DSI(Disparity Space Image) 可以认为是 cost volume 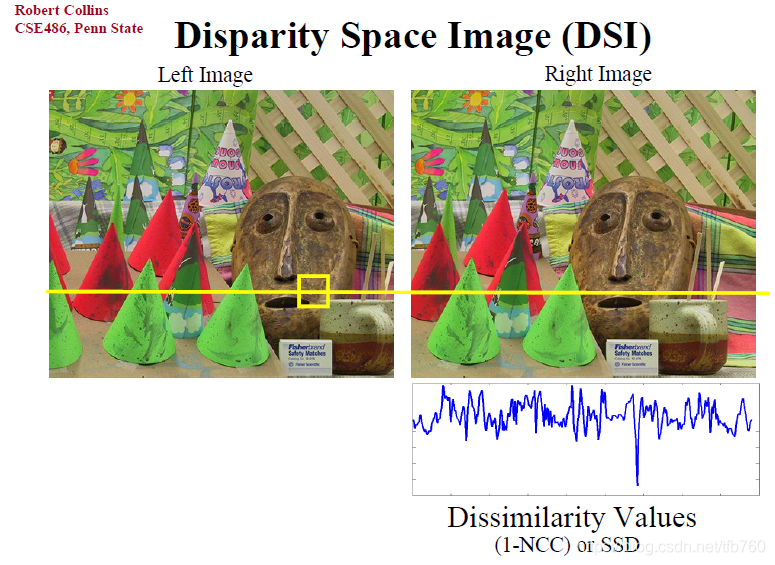 每个DSI对应的是,左目图像中一次scan的结果,即一条极线匹配的结果是一幅DSI DSI 是左图一点对右图极线上的一对多的映射,步长可以是1也可以是其他。DSI 的值可以是匹配代价。
每个DSI对应的是,左目图像中一次scan的结果,即一条极线匹配的结果是一幅DSI DSI 是左图一点对右图极线上的一对多的映射,步长可以是1也可以是其他。DSI 的值可以是匹配代价。 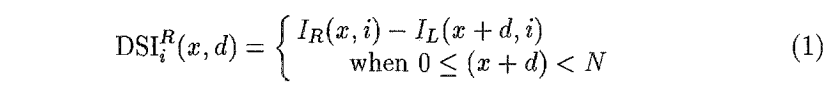 Disparity-Space Images and Large Occlusion Stereo 公式1,也就是极线(epipolar)一条横线上,特征点的:左眼x坐标-右眼x坐标,步长是啥都可以,可以是一个像素也可以是任意的步长
Disparity-Space Images and Large Occlusion Stereo 公式1,也就是极线(epipolar)一条横线上,特征点的:左眼x坐标-右眼x坐标,步长是啥都可以,可以是一个像素也可以是任意的步长
cost volume
计算机视觉中cost-volume的概念具体指什么? - cyouganhou的回答 - 知乎
shape 为(H, W)的左右视图,的所有像素的右视图相对于左视图的全部视差可能值 d 也就取值于一个正整数集合 {0,1,2……..D},若将该正整数集合在视差图的信道维度上进行逐像素表达,那么左右视图对应的 shape 同为(H,W)的视差图就是一个shape为(H,W,D)的搜索空间,也即cost-volume, cost-volume(H,W,D) 的值为可以为匹配代价 还可能 shape 为(C, H, W, D)C 为通道数,比如 RGB 三通道,或者特征通道数
cost aggregation
为什么神经网络也需要代价聚合呢?
局部算法在计算代价时,只考虑了局部的信息,在特征明显的地方能够匹配的较好,但在一些噪声大的边缘区域往往难以匹配,所以采用代价聚合的方法,每个像素在某个视差下的新代价值都会根据其相邻像素在同一视差值或者附近视差值下的代价值来重新计算,得到新的DSI,用矩阵S来表示。这是基于同一深度的像素有相同的视差值的先验知识。 代价聚合也可以理解为视差的传播,让信噪比高的区域的视差传播到信噪比低的区域,使所有点的代价都能较好地表示真实的相关性。 常用的方法:扫描线法、动态规划法、SGM算法中的路径聚合法。
GCNet
GCNet 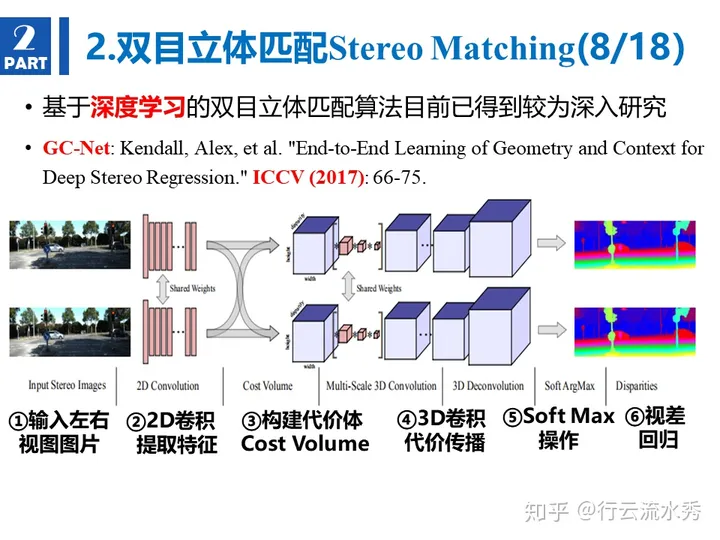 知乎:基于深度学习的双目立体匹配-GCNet、GANet、AANet等
知乎:基于深度学习的双目立体匹配-GCNet、GANet、AANet等
全局立体匹配
全局立体匹配和局部立体匹配是两种不同的立体匹配算法,它们的目的都是从两幅或多幅不同视角的图像中,恢复出场景的三维深度信息。它们的区别主要在于:
匹配范围:局部立体匹配算法只考虑每个像素周围一个小区域内的匹配情况,而全局立体匹配算法考虑整个图像的匹配情况。 优化准则:局部立体匹配算法不构建能量函数,而是利用某种代价函数来比较左右视图中相同大小的图像块来确定视差,而全局立体匹配算法需要构建一个全局的能量函数,来描述匹配的优化准则。 优缺点:局部立体匹配算法的优点是计算速度快,实时性好,适合低算力的平台,缺点是匹配精度低,容易受到噪声和光照的影响,难以处理无纹理区域和深度不连续处。全局立体匹配算法的优点是匹配精度高,鲁棒性强,能够得到更加平滑和连续的视差图,缺点是计算复杂度高,实时性差,需要专用的硬件。
立体匹配算法(局部立体匹配 、全局立体匹配 、深度学习立体匹配 ) 其中像素匹配代价计算和视差图后处理部分与局部立体匹配方法的完全相同,与局部立体匹配方法不同的只在于同时考虑匹配情况的周围像素的范围。
全局立体匹配算法认为图像的视差在全局范围内是平滑的,对于相邻像素视差值相差较大的情况需要加以惩罚,据此构造全局匹配代价函数来代替局部算法中的代价聚合,整个图像上的所有像素同时进行视差值求解。匹配代价函数通常定义如下: \(E(d)=E_{data}(d)+E_{smooth}(d)\) 其中: $E(d)$表示整幅图像中每个像素都各自取了一个视差 d 时的匹配代价; $E_{data}(d)$表示整幅图像所有像素的像素匹配代价之和; $E_{smooth}(d)$表示各像素点与其邻域内像素的视差值之间差值的惩罚项;
全局立体匹配的难点在于如何最小化匹配代价函数的结果,比较典型的求解方法有:
- 在特定路径下寻找最小匹配代价的动态规划算法
- 基于马尔科夫场估计最优解的置信度传播算法
- 采用“最大流”和“最小割”来优化代价函数的图割法